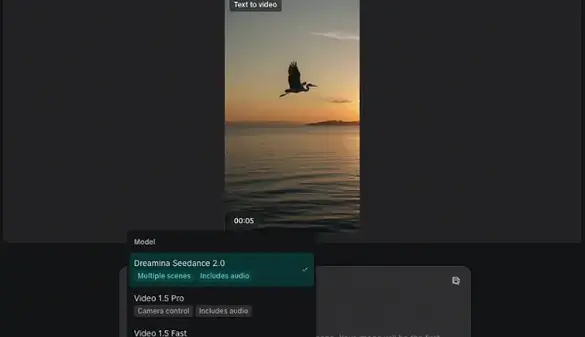
The landscape of digital storytelling is undergoing a transformative shift, driven by advancements in generative models that enhance how creators visualize narratives. Tools like Seedance 2.0 are at the forefront of this evolution, addressing long-standing challenges in AI-generated media, particularly the issue of “identity drift.” By prioritizing character permanence and narrative coherence, these modern generative AIs move beyond producing fragmented clips to facilitating structured storytelling.
For independent filmmakers and marketing professionals, maintaining visual continuity is crucial. An audience’s immersion hinges on a character’s consistent appearance across different camera angles. The latest generative models suggest a future where high-quality visualization can be achieved without the burdensome logistics of traditional film sets. This evolution is not simply about replacing stock footage; it empowers creators to bring their imaginative scenes to life with unprecedented control, surpassing what prompt engineering alone could achieve.
The Engineering Behind Seamless Multi Shot Narrative Flows
The key differentiator among current video generation technologies is their architectural approach to temporal data. Unlike basic frame interpolation methods that often produce incoherent sequences, advanced models employ sophisticated attention mechanisms. This allows systems to retain essential features of subjects, such as clothing texture and facial structures, ensuring consistency even when camera angles change or backgrounds shift.
Identity drift has significantly hindered the use of AI video in professional production workflows. Standard generation often results in characters displaying inconsistent attributes, such as switching from a red jacket to a maroon coat within seconds. Recent technological advancements counter this by separating spatial and temporal processing, locking in a subject’s physical traits before calculating motion.
By anchoring identity data, these models can compute movement without distorting the visual asset—an essential capability for multi-shot storytelling. Observations from technical documentation indicate that the use of Fine-tuned Qwen2.5 language models enables a nuanced interpretation of “director-style” instructions, allowing the AI to understand that a request for a “side profile” pertains to the same character previously described in a “front view” prompt.
Integrating Native Audio Synthesis For Immersive Viewer Experiences
Visual fidelity, while critical, constitutes only half of the cinematic experience; audio plays a pivotal role in immersing viewers in a scene. Historically, AI video generation involved disjointed workflows where visuals were created separately from sound effects. The integration of multimodal learning now allows for the simultaneous generation of video and audio, yielding a cohesive output where the soundscape aligns seamlessly with visual cues.
When a model comprehends the context of a scene, it can predict appropriate audio accompaniment. For instance, if the visuals depict a bustling city street or a quiet rainy window, the system can generate corresponding ambient sounds—traffic noise or raindrops—instantly. This “native audio” capability significantly reduces post-production time. Moreover, basic lip-syncing technology aligns character mouth movements with generated dialogue, enhancing the narrative experience and bridging the gap between silent footage and usable content.
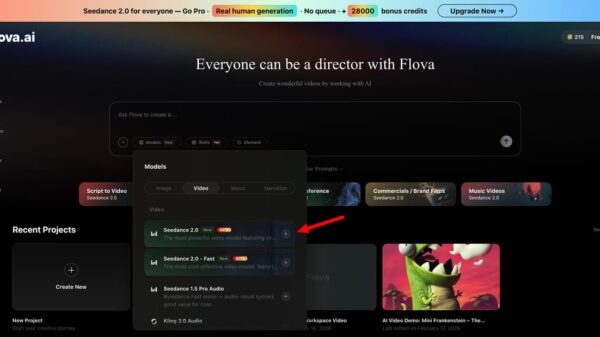
The usability of these high-end generative tools is determined by their interface and process design. High-end technology must be distilled into an accessible workflow for practical daily use. The generation process typically follows a linear path mirroring traditional filmmaking stages, organized into four distinct steps.
The first step initiates with the articulation of a creative concept. Users enter a detailed text prompt or upload reference images, which serve as a creative brief for the AI. This stage is crucial for parsing descriptions regarding characters, settings, and camera movements. Incorporating a reference image enhances the likelihood of outputs aligning with creators’ specific mental images.
Next, users configure high-definition resolution and aspect ratios to meet distribution platform requirements. Options scale up to professional 1080p clarity, with flexibility for different formats tailored to various viewing contexts, ensuring optimal composition without awkward cropping.
Upon generation initiation, the model engages its dual-processing capabilities, synthesizing video frames while simultaneously constructing the audio track. This complex process ensures motion realism and synchronized audio-visual output, merging environmental sounds and dialogue lip-syncing with pixel data.
The final phase involves reviewing the generated content. If standards are met, the video is rendered as a watermark-free MP4 file, optimized for immediate use across social media or further editing. The emphasis is on delivering a “production-ready” asset that minimizes technical intervention for public viewing.
As these technologies evolve, it is essential to understand their current limitations. Output quality remains contingent on the precision of initial input; vague prompts often yield generic results. While the capability for extended video durations up to 60 seconds marks progress, maintaining coherence across longer clips can be computationally demanding. Users may find that shorter clips provide higher fidelity, necessitating the stitching of multiple generations for complete narratives. The present lip-sync functionality, termed “basic,” suggests further refinement is needed to compete with specialized tools for complex dialogues. Creators should regard these tools as powerful assistants for visualization and B-roll creation, rather than instantaneous solutions for comprehensive filmmaking.
See also Generative AI Surpasses Average Human Creativity, But Top Creators Remain Unmatched
Generative AI Surpasses Average Human Creativity, But Top Creators Remain Unmatched AI-Generated Deception: How Fake Reviews and Algorithms Shape Digital Trust
AI-Generated Deception: How Fake Reviews and Algorithms Shape Digital Trust Microsoft Reveals Copilot Canvas: AI-Powered Whiteboard with Image Generation and Streaming Features
Microsoft Reveals Copilot Canvas: AI-Powered Whiteboard with Image Generation and Streaming Features CapCut Unveils AI Video Generation Tools, Enhancing Digital Content Creation for All
CapCut Unveils AI Video Generation Tools, Enhancing Digital Content Creation for All Canva Refutes Job Loss Claims Amid Leonardo.AI Integration, Emphasizes Team Stability
Canva Refutes Job Loss Claims Amid Leonardo.AI Integration, Emphasizes Team Stability