The rapid advancement of artificial intelligence (AI) has encountered a significant challenge: the efficient training of large language models (LLMs) capable of performing complex reasoning tasks. Conventional reinforcement learning (RL) methods often struggle with the high computational costs associated with generating lengthy responses. However, recent research from Qinghao Hu, Shang Yang, and Junxian Guo, along with their colleagues at MIT and other institutions, presents a groundbreaking system designed to expedite this training process significantly.
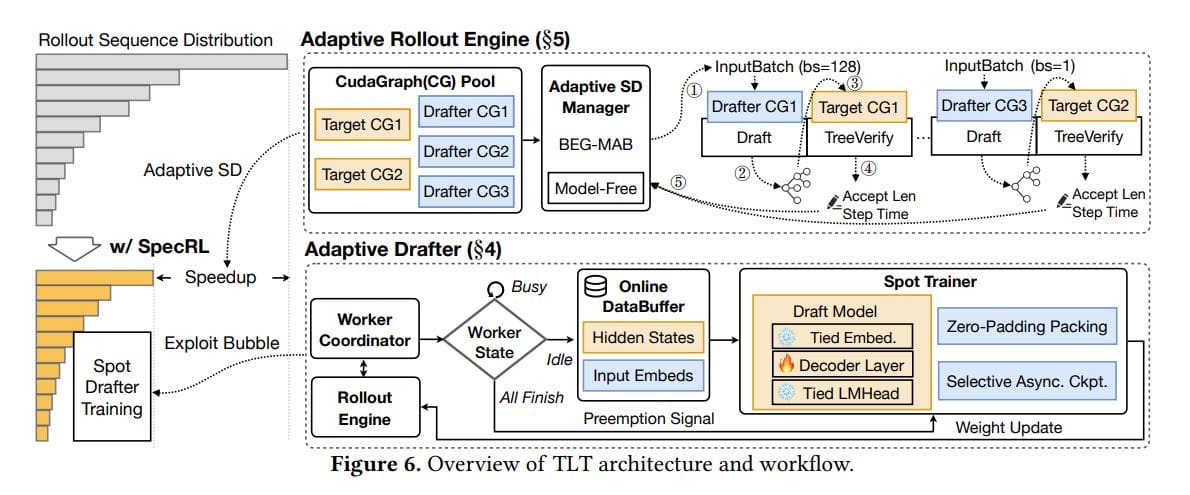
The research addresses a critical issue in response generation—known as the ‘long-tail’ distribution—where a small number of exceptionally long outputs disproportionately slow down the training process. Their innovative solution, dubbed TLT, integrates adaptive speculative decoding with a continuously trained component called the “Adaptive Drafter.” This combination results in a remarkable increase in training speeds, achieving over a 1.7 times speedup without compromising the models’ accuracy. Additionally, TLT generates a high-quality draft model as a valuable byproduct, enhancing the overall efficiency of deployment.
Innovative Approach to Reinforcement Learning
Reinforcement Learning has often faced efficiency bottlenecks due to the long-tail distribution of response times. In this context, a few very lengthy responses can dominate overall execution time, leading to wasted computational resources and inflated costs. The TLT system addresses these challenges effectively, offering a lossless acceleration in RL training. By employing adaptive speculative decoding, TLT predicts likely responses, streamlining the inference process while maintaining accuracy.
Nevertheless, applying speculative decoding in RL presents various challenges, including dynamic workloads and the need for real-time training. TLT overcomes these obstacles through its dual components: the Adaptive Drafter, which is a lightweight draft model continuously trained on idle GPUs, and the adaptive speculative decoding mechanism that optimizes workload distribution and response generation.
Performance Metrics and Evaluation
The performance of TLT was rigorously evaluated across multiple GPU platforms, including the NVIDIA H100 and A100, with varying scales of language models. The results consistently demonstrated that TLT outperforms existing systems, achieving significant gains across different hardware generations. Specifically, when using models like Qwen2.5-7B and Qwen2.5-32B, the researchers noted average reward curves indicating that acceleration was accomplished without altering learning dynamics.
Measurements across various models, including Qwen-7B, DeepSeek-7B, Qwen-32B, and Llama-70B, further illustrate the effectiveness of TLT. The research team found that the tuning of draft depth and token verification significantly influences performance, with optimal configurations yielding substantial speed improvements. For instance, using the Qwen-32B model on H100 GPUs showcased remarkable efficiencies, particularly with larger batch sizes, which benefited from fewer tokens being verified.
Broader Implications for AI Training
The development of TLT not only represents a significant technical achievement but also addresses broader issues in AI model training. As researchers continue to explore frameworks like Reinforcement Learning from Human Feedback (RLHF) and optimization techniques such as stage fusion, the need for robust evaluation methods becomes increasingly vital. Tools like MT-Bench and Chatbot Arena have emerged to assess LLM performance, highlighting the growing emphasis on aligning AI models with human preferences.
Moreover, TLT’s adaptability is a key advantage, allowing it to adjust to ongoing changes in target models during training and varying batch sizes during inference. The released code enables further exploration and application of adaptive speculative decoding, promising a new avenue for enhancing the efficiency and effectiveness of advanced language models.
In summary, the TLT system offers a transformative approach to training large language models, tackling inefficiencies inherent in traditional RL methods. Its promising results could pave the way for more efficient AI systems capable of complex reasoning, enhancing the overall landscape of artificial intelligence.
 Generative AI Needs Traditional Machine Learning for 95% Accuracy in Business Decisions
Generative AI Needs Traditional Machine Learning for 95% Accuracy in Business Decisions BNX Payments Launches BNX AI: Free, Registration-Free Image Generation for All Users
BNX Payments Launches BNX AI: Free, Registration-Free Image Generation for All Users Erotic AI Platform Secret Desires Exposes 2 Million Images, Including Private Citizens
Erotic AI Platform Secret Desires Exposes 2 Million Images, Including Private Citizens IIT Patna and Adobe Research Launch TAI Framework for Translating 1,570 Indian Poems
IIT Patna and Adobe Research Launch TAI Framework for Translating 1,570 Indian Poems Google CEO Urges Caution on AI Trustworthiness as Gemini 3.0 Launches
Google CEO Urges Caution on AI Trustworthiness as Gemini 3.0 Launches