



















































In a significant advancement for the field of artificial intelligence, a team of researchers at NVIDIA has introduced an innovative framework known as Nemotron Elastic. This framework addresses the challenges associated with training large language models (LLMs), specifically the high computational costs and resource demands that typically accompany the process of developing multiple models for various applications. The researchers, including Ali Taghibakhshi, Sharath Turuvekere Sreenivas, and Saurav Muralidharan, have demonstrated that their method can efficiently derive reasoning-oriented language models from a single parent model.
Revolutionizing LLM Training
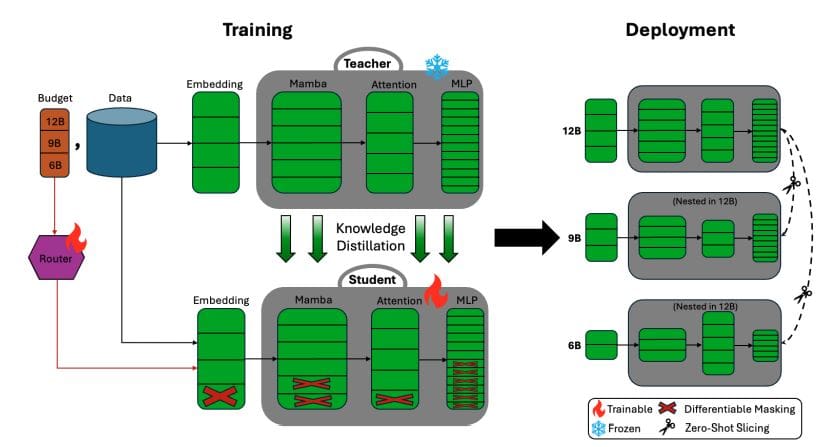
The primary breakthrough of Nemotron Elastic lies in its ability to create nested sub-models within a single parent structure, allowing for the generation of smaller, optimized models with minimal additional training. This approach results in a remarkable reduction in the computational resources needed—over a 360-fold reduction compared to training models from scratch and a seven-fold improvement over traditional compression methods. Specifically, the research focuses on the Nemotron Nano V2 12B model, from which 9B and 6B versions can be produced using only 110 billion training tokens while preserving or even enhancing accuracy.
The team emphasizes that their method confronts a crucial challenge in the AI landscape: the financial burden associated with maintaining multiple LLMs tailored for various tasks. By adopting a hybrid Mamba-Transformer architecture and emphasizing extended-context training, Nemotron Elastic offers a versatile solution adaptable to different scales and applications. One of the key innovations of this framework is the incorporation of extended-context training, which utilizes sequences of 49,000 tokens. This technique is vital for maintaining reasoning performance in the smaller models derived from the parent model.
Efficiency Through Nested Sub-Networks
Another notable aspect of Nemotron Elastic is its capability to extract smaller, nested models from the larger parent model on-the-fly, requiring no further training or fine-tuning. This enables organizations with limited resources to deploy powerful reasoning models tailored to their specific needs. Importantly, the framework maintains a constant deployment memory footprint regardless of the number of models produced, contrasting sharply with conventional methods where memory requirements increase proportionately with the number of models.
The framework’s efficiency stems from several innovations in its training process. Key components include importance-based component ranking for architectural priorities, frozen teacher knowledge distillation for optimizing joint sub-networks, and an end-to-end trained router that adjusts architectural decisions based on task difficulty. These advancements collectively contribute to the ability of Nemotron Elastic to facilitate efficient training of reasoning models across different computational budgets.
Implications for the AI Community
The introduction of Nemotron Elastic represents a pivotal moment in the AI field, particularly regarding the democratization of access to advanced reasoning models. This breakthrough has the potential to empower organizations with modest computational budgets to leverage sophisticated LLMs tailored to their requirements. Moving forward, researchers are exploring ways to scale this framework to even larger model families and to investigate dynamic routing mechanisms for inference that could further enhance the flexibility and efficiency of LLM deployment.
As the AI landscape evolves, the innovations presented by the NVIDIA team could redefine how organizations approach the development and deployment of large language models, addressing both the economic and technical challenges that have historically limited access to advanced AI capabilities. The implications of this research are vast, potentially enabling a broader range of applications and fostering further advancements in AI reasoning capabilities.
 OpenAI Halts FoloToy Sales After Kumma Bear’s Inappropriate Conversations Raise Safety Concerns
OpenAI Halts FoloToy Sales After Kumma Bear’s Inappropriate Conversations Raise Safety Concerns AI-Generated Images: Can You Identify the 5 AI Creations Among 10 Real-Life Photos?
AI-Generated Images: Can You Identify the 5 AI Creations Among 10 Real-Life Photos? Five Generative Models: Key Strengths and Use Cases for AI Professionals
Five Generative Models: Key Strengths and Use Cases for AI Professionals OpenAI’s GPT-5 Launch Faces Backlash on Reddit, Sam Altman Responds to Criticism
OpenAI’s GPT-5 Launch Faces Backlash on Reddit, Sam Altman Responds to Criticism Charter Announces AWS AI Partnership, Aiming for Enhanced Efficiency and Customer Experience
Charter Announces AWS AI Partnership, Aiming for Enhanced Efficiency and Customer Experience















