














































Researchers from the University of Southern California and the University of California, Davis, along with collaborators from Microsoft Research, have unveiled a novel framework called BeMyEyes aimed at enhancing the capabilities of large language models (LLMs) to process both text and images. The team, led by James Y. Huang, has developed a system that circumvents the significant resource demands typically associated with constructing integrated vision-language models. Instead of requiring extensive retraining, BeMyEyes orchestrates collaboration between smaller, agile vision-language models (VLMs) acting as “perceivers” and robust language models that serve as “reasoners.” This innovative multi-agent system facilitates multimodal reasoning, allowing a compact open-source language model to outperform larger proprietary vision-language models in complex, knowledge-intensive tasks, thereby paving the path for more adaptable artificial intelligence systems.
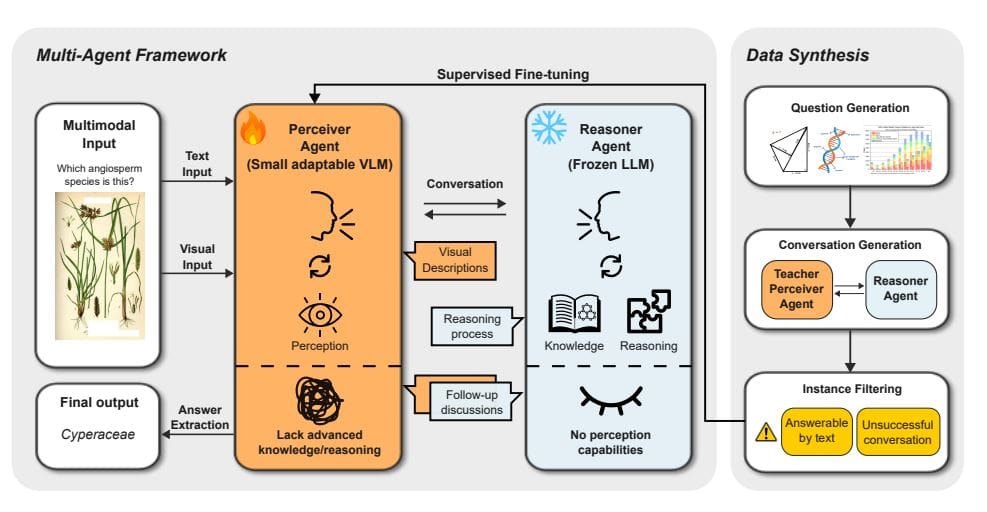
The research details a specific application of this framework, known as B. Prompt, designed to tackle multiple-choice questions related to images. Utilizing a three-agent approach, the system enhances performance in visual question-answering tasks by simplifying complex issues into smaller, more manageable segments. Each agent has a distinct role: the Perceiver Agent focuses on describing the image, the Reasoner Agent coordinates the overall process while interrogating the Perceiver for details, and the Expert—part of the Reasoner—synthesizes information to deliver the conclusive answer. The process begins with the Reasoner extracting answers from an initial prompt that includes both the question and image descriptions, ultimately formatting responses as “Answer: $LETTER.”
BeMyEyes aims to expand the capabilities of LLMs into the realm of multimodal reasoning through collaborative efforts between adaptable vision-language models and powerful LLMs. This decoupling of perception from reasoning enables text-only language models to interpret visual data without the extensive retraining often required by traditional approaches. The framework features a perceiver agent implemented with a small, computationally efficient VLM, working alongside a reasoner agent that utilizes a frozen LLM with substantial knowledge and reasoning prowess. This modular architecture allows for the flexible integration of new perceiver or reasoner models into the system.
The research team established an effective conversational flow between the perceiver and reasoner agents, with the perceiver concentrating on interpreting visual input and communicating pertinent details while the reasoner actively queries for specific information. The perceiver is prompted to recognize the reasoner’s lack of direct visual perception, which encourages more detailed descriptions. A dedicated data synthesis pipeline and a supervised fine-tuning strategy were developed to enhance the perceiver agent’s ability to accurately interpret visual information and respond effectively to the reasoner’s inquiries. Experiments demonstrated the efficacy of this approach across diverse tasks, models, and domains, establishing BeMyEyes as a scalable and flexible alternative to large-scale multimodal models.
When the researchers equipped the text-only DeepSeek-R1 LLM with the Qwen2 5-VL-7B perceiver agent, the combination outperformed larger proprietary vision-language models, including GPT-4o, on several knowledge-intensive multimodal tasks. On the MathVista benchmark, this configuration achieved a score of 72.7, surpassing GPT-4o’s score of 68.3. Similarly, on the MMMU-Pro benchmark, the pairing delivered a score of 57.2, outpacing GPT-4o’s score of 49.
Through the creation of the data synthesis pipeline, the researchers effectively distilled perceptual and instruction-following capabilities from larger VLMs to enhance the perceiver agent’s communication of visual information to the reasoner. The results confirm that BeMyEyes significantly elevates the performance of text-only LLMs in multimodal reasoning tasks, presenting a modular, scalable, and flexible alternative to traditional large-scale multimodal models. This reduces computational costs while maintaining generalization capabilities, marking a significant advancement in the development of future multimodal reasoning systems.
As the field of artificial intelligence continues to evolve, frameworks like BeMyEyes not only demonstrate the potential for improved multimodal reasoning but also signify a shift towards more efficient and adaptable AI systems. This innovative approach may lead to broader applications across various domains, fostering advancements in how AI interprets and interacts with the world.
👉 More information
🗞 Be My Eyes: Extending Large Language Models to New Modalities Through Multi-Agent Collaboration
🧠 ArXiv: https://arxiv.org/abs/2511.19417
 Johns Hopkins Researchers Unveil CWMDT for Superior Counterfactual Video Predictions
Johns Hopkins Researchers Unveil CWMDT for Superior Counterfactual Video Predictions Diffusion Transformers Enhance Mixed-Resolution Denoising with Phase-Aligned Attention
Diffusion Transformers Enhance Mixed-Resolution Denoising with Phase-Aligned Attention Alibaba Cloud Recognized as Emerging Leader in All Four Gartner Generative AI Quadrants
Alibaba Cloud Recognized as Emerging Leader in All Four Gartner Generative AI Quadrants Black Forest Labs Launches FLUX.2 VAE, Enabling Custom AI Image Generation for Enterprises
Black Forest Labs Launches FLUX.2 VAE, Enabling Custom AI Image Generation for Enterprises Slop Evader Launches Tool to Filter Web Content to Pre-GPT Era, Combat AI Overload
Slop Evader Launches Tool to Filter Web Content to Pre-GPT Era, Combat AI Overload



















