










































Researchers at Johns Hopkins University have developed a groundbreaking framework in artificial intelligence that enables AI systems to answer counterfactual questions about video content. The team, comprising Yiqing Shen, Aiza Maksutova, Chenjia Li, and Mathias Unberath, aims to enhance our understanding of how visual scenes might change under hypothetical scenarios, transcending traditional video forecasting. Their innovative method, which constructs ‘digital twins’ of observed scenes, allows researchers to simulate the effects of removing objects or altering scenes in ways previously considered unattainable.
This research is part of a broader effort in the rapidly evolving field of video generation and understanding, particularly focusing on text-to-video generation. This area seeks to improve video quality, controllability, and realism from text prompts. Significant advancements are also being made in developing world models—AI systems that internalize environmental representations and predict future states. Innovations in video editing and manipulation, such as object removal and style transfer, are pivotal to these efforts. Notably, digital twins, which provide virtual representations of real-world environments, are enhancing the reasoning and planning capabilities of AI systems.
At the core of this advancement is the integration of Large Language Models (LLMs), which play a crucial role in enabling these systems to understand instructions and generate coherent content. Diffusion models have emerged as a leading approach for text-to-video generation, celebrated for their ability to deliver high-quality outputs. Researchers are continuously working on new benchmarks and evaluation metrics to assess the performance of these models while addressing concerns related to fairness and bias. Moreover, there is a push to develop scalable and efficient models that can handle high-resolution videos and complex scenes, linking world models with embodied agents to facilitate interactions with the physical world.
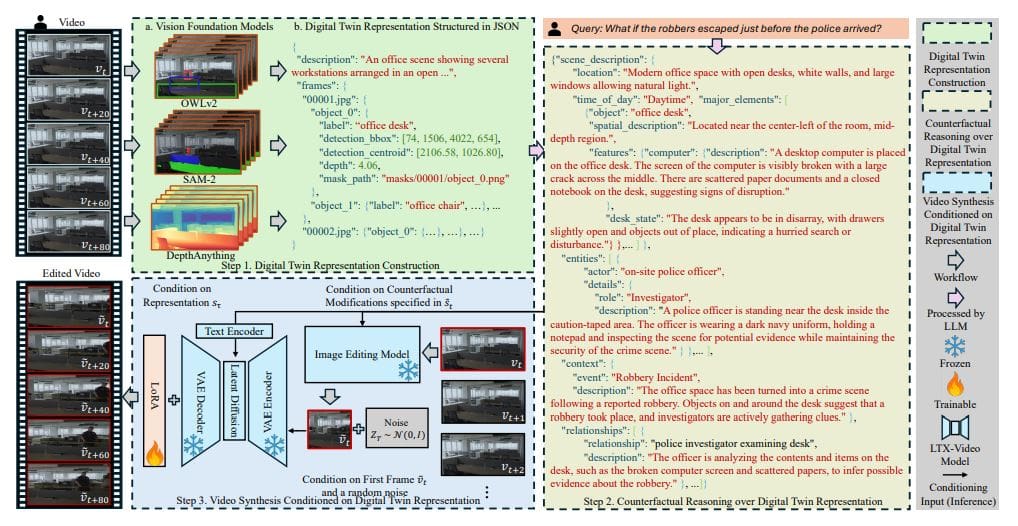
The newly introduced Counterfactual World Model with Digital Twins (CWMDT) stands out as a unique system that predicts how visual scenes can evolve through hypothetical changes. Unlike traditional world models that focus solely on factual observations, CWMDT empowers researchers to explore “what if” scenarios, such as the implications of removing an object from a scene. This is accomplished through the creation of digital twins that represent objects and their relationships in a structured text format, allowing targeted interventions that are not possible with pixel-based methods.
The process begins by transforming each video frame into a digital twin representation, utilizing advanced vision foundation models. Tools like SAM-2 perform object segmentation, tracking them across frames, while DepthAnything assesses the spatial positioning of objects. Meanwhile, OWLv2 categorizes detected instances semantically, and QWen2.5-VL generates natural language descriptions of object attributes. This structured representation is then serialized in JSON format, shifting the focus from visual reasoning to textual analysis, crucial for the subsequent intervention mapping.
In this innovative system, an LLM analyzes proposed interventions, predicts their temporal evolution within the digital twin framework, and identifies affected objects and relationships. This allows for forecasting how changes propagate over time, leveraging the LLM’s embedded world knowledge. The modified digital twin representation is subsequently fed into a video diffusion model, which generates a counterfactual video sequence that reflects the anticipated changes. Evaluations against benchmark datasets indicate that CWMDT achieves state-of-the-art performance, showcasing the efficacy of explicit representations like digital twins in enhancing video forward simulation.
Experimental results further underline the advantages of CWMDT, which significantly outperforms existing video generative models across various metrics and complexity levels. Notably, it scores 33.33% on the GroundingDINO metric at the highest complexity level, reflecting its precision in localizing intervention targets, and achieves 64.06% on the LLM-as-a-Judge metric, indicating improved alignment of counterfactual outcomes with the intended intervention semantics. The critical roles of digital twin representations and LLM-based reasoning were confirmed through ablation studies, which revealed that the removal of either component led to a marked decrease in performance.
This research not only demonstrates the capabilities of CWMDT to generate diverse and plausible counterfactual scenarios but also establishes a framework that could redefine how we interact with AI in video simulation and understanding. As the field continues to evolve, the integration of advanced models like CWMDT suggests promising avenues for future developments in artificial intelligence, potentially paving the way for more robust and flexible AI simulations across various applications.
See also Diffusion Transformers Enhance Mixed-Resolution Denoising with Phase-Aligned Attention
Diffusion Transformers Enhance Mixed-Resolution Denoising with Phase-Aligned Attention Alibaba Cloud Recognized as Emerging Leader in All Four Gartner Generative AI Quadrants
Alibaba Cloud Recognized as Emerging Leader in All Four Gartner Generative AI Quadrants Black Forest Labs Launches FLUX.2 VAE, Enabling Custom AI Image Generation for Enterprises
Black Forest Labs Launches FLUX.2 VAE, Enabling Custom AI Image Generation for Enterprises Slop Evader Launches Tool to Filter Web Content to Pre-GPT Era, Combat AI Overload
Slop Evader Launches Tool to Filter Web Content to Pre-GPT Era, Combat AI Overload Lei Unveils Improved GAN-LSTM Method Boosting Fake Face Detection Accuracy by 30%
Lei Unveils Improved GAN-LSTM Method Boosting Fake Face Detection Accuracy by 30%