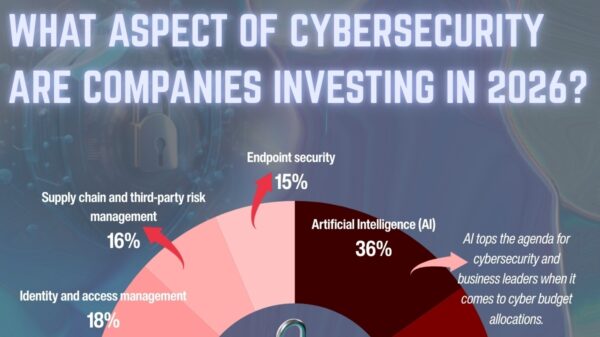


































The artificial intelligence landscape has been significantly transformed with the release of Chatterbox Turbo, an advanced open-source text-to-speech (TTS) model by Resemble AI. Announced on December 15, 2025, this model aims to democratize high-quality, real-time voice generation, featuring ultra-low latency, exceptional emotional control, and an integrated watermarking system designed for ethical AI use. Chatterbox Turbo marks a critical development in the domain of open-source voice AI, setting new standards for expressiveness, speed, and reliability in synthetic media.
Chatterbox Turbo’s immediate importance lies in its ability to enhance the naturalness and responsiveness of conversational AI agents, all while addressing rising concerns regarding deepfakes and the integrity of AI-generated content. By providing a robust, production-grade solution under an MIT license, Resemble AI is empowering a vast array of developers and enterprises to incorporate sophisticated voice capabilities into their applications—ranging from interactive media to virtual assistants. This shift heralds an unprecedented wave of innovation within the voice AI sector.
Technical Details
At the core of Chatterbox Turbo’s performance is its streamlined architecture, encompassing 350 million parameters, which marks a significant optimization over previous iterations of the Chatterbox model. While the broader Chatterbox family utilizes a 0.5 billion Llama backbone refined on 500,000 hours of audio data, Turbo’s innovation lies in its distillation of the speech-token-to-mel decoder. This breakthrough reduces the speech generation process from ten steps to a single, highly efficient action, allowing the model to produce speech up to six times faster than real-time on a GPU. It achieves an impressive sub-200-millisecond time-to-first-sound latency, making it ideal for real-time applications.
Chatterbox Turbo stands apart from both proprietary and other open-source models due to several unique features. Unlike many commercial TTS solutions, it is fully open-source and MIT licensed, which offers developers the freedom of local operability without the burden of per-word fees or vendor lock-in. The model’s efficiency is amplified by its capacity to deliver high-quality voice synthesis with diminished computational power and VRAM. Additionally, it enhances zero-shot voice cloning, requiring just five seconds of reference audio—an improvement over many competitors that demand longer samples. Native integration of paralinguistic tags such as [cough], [laugh], and [chuckle] adds layers of realism to generated speech.
Two standout features further distinguish Chatterbox Turbo: Emotion Exaggeration Control and PerTh Watermarking. The model is the first open-source TTS to offer detailed control over emotional delivery, enabling users to modify the intensity of voice expression with a single parameter. This level of nuance exceeds basic emotion settings available in many competing services. The PerTh watermark employs a deep neural network to embed undetectable data within inaudible sound ranges, ensuring authenticity of AI-generated content. This watermark can withstand common manipulations like MP3 compression, achieving nearly 100% detection accuracy which directly combats the threats posed by deepfakes.
Initial feedback from the AI research community has been overwhelmingly positive. Discussions across platforms like Hacker News and Reddit reflect widespread acclaim for its production-grade quality and the flexibility of its MIT license. Many researchers have noted its superior performance against closed-source systems such as ElevenLabs (NASDAQ: ELVN) in blind evaluations, especially regarding cloning capabilities, emotional control, and open-source accessibility. Experts are particularly enthusiastic about the potential of emotion exaggeration control and PerTh watermarking, labeling them as “game-changers.” While some minor critiques have emerged regarding audio generation limits for lengthy texts, the consensus strongly favors Chatterbox Turbo as a significant advancement for open-source TTS.
The arrival of Chatterbox Turbo is set to stir the AI industry, creating abundant opportunities and competitive pressures. Startups focusing on voice technology, content creation, and customer service stand to gain immensely, as the MIT open-source license eliminates the high costs typically associated with proprietary TTS solutions. This democratization opens doors for smaller players to develop innovative, personalized customer experiences. Content creators, including podcasters and game developers, will find Chatterbox Turbo invaluable for producing dynamic audio content more affordably and efficiently.
However, for major AI labs and tech giants, such as Alphabet (NASDAQ: GOOGL) and Microsoft (NASDAQ: MSFT), Chatterbox Turbo’s emergence poses both challenges and opportunities. Companies offering proprietary TTS services will likely feel increased competitive pressure, particularly as Chatterbox Turbo claims to outperform them in blind evaluations. This situation could compel incumbents to reassess their pricing strategies and feature sets, while also considering open-sourcing aspects of their own models. As the landscape evolves, the focus may shift from basic TTS solutions to specialized services that leverage established cloud infrastructures for enterprise support.
Chatterbox Turbo is not merely a milestone; it is part of a broader trend towards more ethical and responsible AI deployment. While its powerful voice synthesis capabilities promise to enhance customer support and revolutionize content creation, they also raise ethical considerations about the potential misuse of voice cloning technology. The model’s watermarking system helps address authenticity concerns, but the societal implications of indistinguishable AI-generated voices could create challenges in trust and authenticity in audio content. As the AI voice sector continues to evolve, the integration of ethical safeguards will be crucial in ensuring responsible usage.
In summary, the launch of Chatterbox Turbo represents a landmark achievement in the AI landscape, offering cutting-edge features that challenge traditional notions of proprietary voice technologies. As we look ahead, the focus will be on how widely and effectively this model is adopted across various industries and how it shapes the future of human-computer interaction through voice. The ongoing discourse surrounding ethical AI will be equally vital, making responsible practices an integral part of future developments in the field.
See also Unlock Powerful Local AI: 7 Advanced Uses for Your PC Beyond Chatbots and Images
Unlock Powerful Local AI: 7 Advanced Uses for Your PC Beyond Chatbots and Images Adobe Unveils Firefly Video Editor with Unlimited Generations, New AI Editing Tools
Adobe Unveils Firefly Video Editor with Unlimited Generations, New AI Editing Tools AI Detection Challenges: 5 Lessons from 2025’s Deepfake Surge and Future Implications
AI Detection Challenges: 5 Lessons from 2025’s Deepfake Surge and Future Implications Shanghai AI Lab Launches MemVerse: First Universal Multimodal Memory Framework for Agents
Shanghai AI Lab Launches MemVerse: First Universal Multimodal Memory Framework for Agents AI Framework Achieves 79% Accuracy in Ranking Educational Resources for Personalized Learning
AI Framework Achieves 79% Accuracy in Ranking Educational Resources for Personalized Learning