






























In a breakthrough that could reshape the landscape of natural language processing (NLP), Tonic Textual has introduced a custom entity workflow that significantly reduces the costs associated with human annotation in named entity recognition (NER). This innovation comes at a time when the demand for high-quality training data is growing, yet the traditional methods of data annotation remain slow and expensive.
The NCBI Disease Corpus serves as a prime example of the challenges involved in building quality training sets. Developed over two summers by 14 annotators with biomedical informatics backgrounds, the corpus required painstaking efforts to label 793 abstracts from PubMed, with each document independently reviewed to ensure accuracy. The labor-intensive process illustrates the broader issue facing NER: recruiting domain experts and managing multi-annotator projects can be prohibitively costly, especially in specialized fields like healthcare and finance.
Tonic Textual’s approach aims to streamline this process by leveraging large language models (LLMs) to automate the annotation phase. By writing clear annotation guidelines and uploading a small validation set of ground truth labels, practitioners can refine their instructions and let the LLM handle the bulk of the data annotation. This innovative method allows for rapid processing of thousands of documents, thereby addressing the traditional bottleneck in NER.
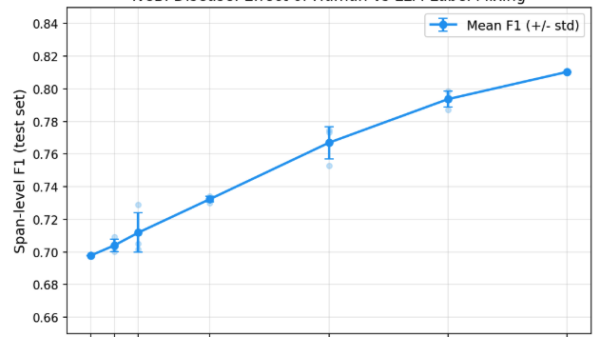
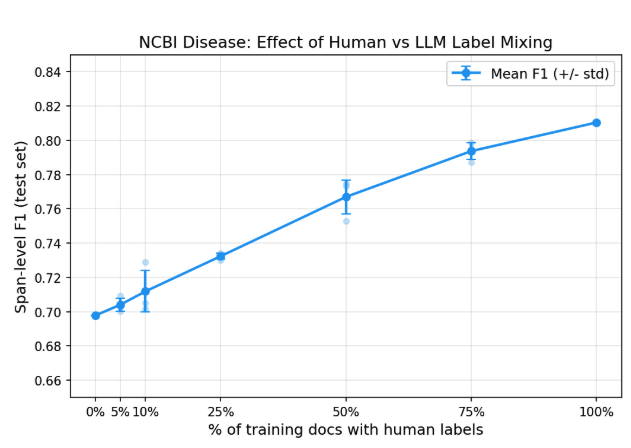
The effectiveness of this method was put to the test using the NCBI Disease Corpus. In a controlled experiment, Tonic Textual found that LLM annotations yielded a model with an F1 score of 0.71 against ground truth labels, even with no human-labeled training data. This score improved incrementally as more human labels were mixed in, reaching an F1 score of 0.81 with complete human annotations. However, the returns diminished with each additional document, signaling that the core value lies in the effective guidelines rather than extensive human labeling.
When compared with other approaches, Tonic Textual’s custom entity workflow demonstrated a significant advantage. While GLiNER2, a zero-shot NER model, achieved a low recall rate of 0.26 despite good precision, Tonic’s method excelled with minimal human input. A mere ten human-labeled validation examples allowed the model to achieve an F1 score of 0.71, underscoring the potential of this new annotation strategy.
Despite the success, a lingering question remains regarding the limitations of using general-purpose models such as RoBERTa. The authors acknowledge that specialized biomedical models could close the performance gap, which currently sits between 0.70 and 0.81 F1. The polysemy of gene and disease names presents a unique challenge, as abbreviations often refer to both, complicating the annotation process.
In a subsequent case study involving healthcare identifiers from electronic health records (EHR), Tonic Textual further reinforced the efficacy of its approach. The workflow began with a validation set of 123 documents and expanded to a training set of 1,119 documents, all annotated by the LLM. Iterative refinement of guidelines led to a final model achieving an impressive F1 score of 0.947, surpassing the production release threshold of 0.914. Notably, this was accomplished with no human-labeled training data, emphasizing the potential for rapid and cost-effective deployment of NER models.
As Tonic Textual continues to break down the barriers posed by traditional annotation processes, the implications for industries relying on NER are profound. The workflow compresses weeks of labor-intensive tasks into a matter of hours, allowing organizations to shift their focus from data collection to refining their understanding of what they seek to extract. With the ability to produce production-ready models swiftly, Tonic Textual is poised to change how practitioners approach NER, making high-quality data annotation accessible and efficient.
The implications of this advancement resonate across sectors that utilize NER technology. As organizations look to improve their data extraction capabilities without incurring prohibitive costs, Tonic Textual’s custom entity workflow offers a promising solution to a longstanding challenge in the NLP space.
See also Sam Altman Praises ChatGPT for Improved Em Dash Handling
Sam Altman Praises ChatGPT for Improved Em Dash Handling AI Country Song Fails to Top Billboard Chart Amid Viral Buzz
AI Country Song Fails to Top Billboard Chart Amid Viral Buzz GPT-5.1 and Claude 4.5 Sonnet Personality Showdown: A Comprehensive Test
GPT-5.1 and Claude 4.5 Sonnet Personality Showdown: A Comprehensive Test Rethink Your Presentations with OnlyOffice: A Free PowerPoint Alternative
Rethink Your Presentations with OnlyOffice: A Free PowerPoint Alternative OpenAI Enhances ChatGPT with Em-Dash Personalization Feature
OpenAI Enhances ChatGPT with Em-Dash Personalization Feature