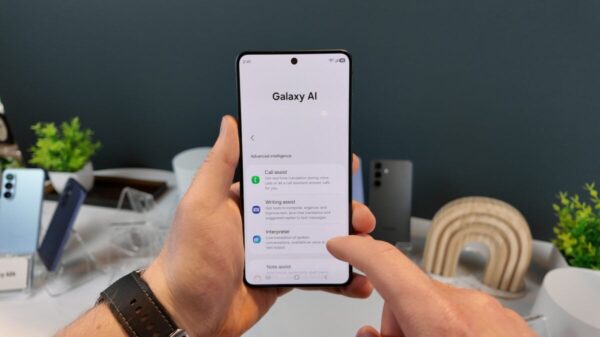



































In a groundbreaking announcement, Samsung has unveiled innovative compression technology that enables cloud-level AI capabilities on smartphones. This breakthrough allows a 30-billion-parameter AI model, which would typically require over 16GB of memory, to operate using less than 3GB on a mobile device. Dr. MyungJoo Ham of the Samsung Research AI Center detailed these advancements in an exclusive interview, illustrating how the company aims to enhance the intelligence of smartphones to rival that of cloud-based systems.
The innovations from Samsung promise to redefine the boundaries of mobile AI. The research team has achieved a feat that many believed impractical just months ago, enabling massive AI models to run locally on devices. Dr. Ham explained, “Running a highly advanced model that performs billions of computations directly on a smartphone would quickly drain the battery, increase heat, and slow response times. Model compression technology emerged to address these issues.”
At the heart of this technology lies a sophisticated quantization process, akin to photo compression, which maintains visual quality while significantly reducing file sizes. Samsung’s proprietary algorithms transform 32-bit floating-point calculations into 8-bit or even 4-bit integers, thereby drastically cutting down both memory usage and computational load.
What sets Samsung’s approach apart is its nuanced understanding of neural network weights. Dr. Ham noted that not all components of an AI model carry equal significance. The compression methodology identifies critical neural network weights, ensuring their preservation at higher precision while more aggressively compressing less important elements. “Because each model weight has a different level of importance, we preserve critical weights with higher precision while compressing less important ones more aggressively,” he stated.
Introducing the AI Runtime Engine
Samsung has also developed an “AI runtime engine,” which acts as the engine control unit for AI models running on smartphones. This component functions like a smart traffic controller, determining the optimal processor—CPU, GPU, or NPU—to execute each operation efficiently. This strategic allocation minimizes memory access, ensuring maximum performance for AI tasks on mobile devices. “The AI runtime is essentially the model’s engine control unit,” Dr. Ham explained. “When a model runs across multiple processors, the runtime automatically assigns each operation to the optimal chip and minimizes memory access to boost overall AI performance.”
The implications of these advancements are vast. With the ability to run sophisticated AI models directly on smartphones, users can expect enhanced functionalities previously limited to cloud computing. This shift not only promises faster response times but also improved user experiences across applications, from virtual assistants to real-time data processing.
As the competition in the mobile AI space intensifies, Samsung’s compression technology positions it at the forefront of innovation. By successfully integrating such advanced AI capabilities into smartphones, the company is paving the way for a future where mobile devices become increasingly autonomous and capable of processing complex tasks without relying solely on cloud infrastructures.
In summary, Samsung’s developments in AI compression and the introduction of an efficient runtime engine are significant steps toward making smartphones more intelligent and user-friendly. As these technologies continue to evolve, they could fundamentally alter how we interact with our devices and leverage AI in daily life.
See also Trump’s Draft Order Aims to Block State AI Regulations, Sparking Bipartisan Concern
Trump’s Draft Order Aims to Block State AI Regulations, Sparking Bipartisan Concern Samsung Reveals 30B Parameter AI Model Running on Just 3GB Memory for Smartphones
Samsung Reveals 30B Parameter AI Model Running on Just 3GB Memory for Smartphones Wichita Police Deploy Axon AI for Real-Time Translation in Over 50 Languages
Wichita Police Deploy Axon AI for Real-Time Translation in Over 50 Languages Samsung Achieves 30B-Parameter AI Model on 3GB Memory Using Breakthrough Compression
Samsung Achieves 30B-Parameter AI Model on 3GB Memory Using Breakthrough Compression Asseta AI Secures $4.2M to Enhance Intelligent Financial Tech for Family Offices
Asseta AI Secures $4.2M to Enhance Intelligent Financial Tech for Family Offices