Researchers at Carnegie Mellon University have unveiled Image2Gcode, an innovative deep learning framework capable of generating printer-ready G-code directly from 2D images. This breakthrough eliminates the traditional reliance on computer-aided design (CAD) models and slicing software, streamlining the additive manufacturing process. The findings, published on arXiv, highlight a diffusion-transformer model that converts sketches or photographs into executable manufacturing instructions, establishing a direct connection between visual design and fabrication.
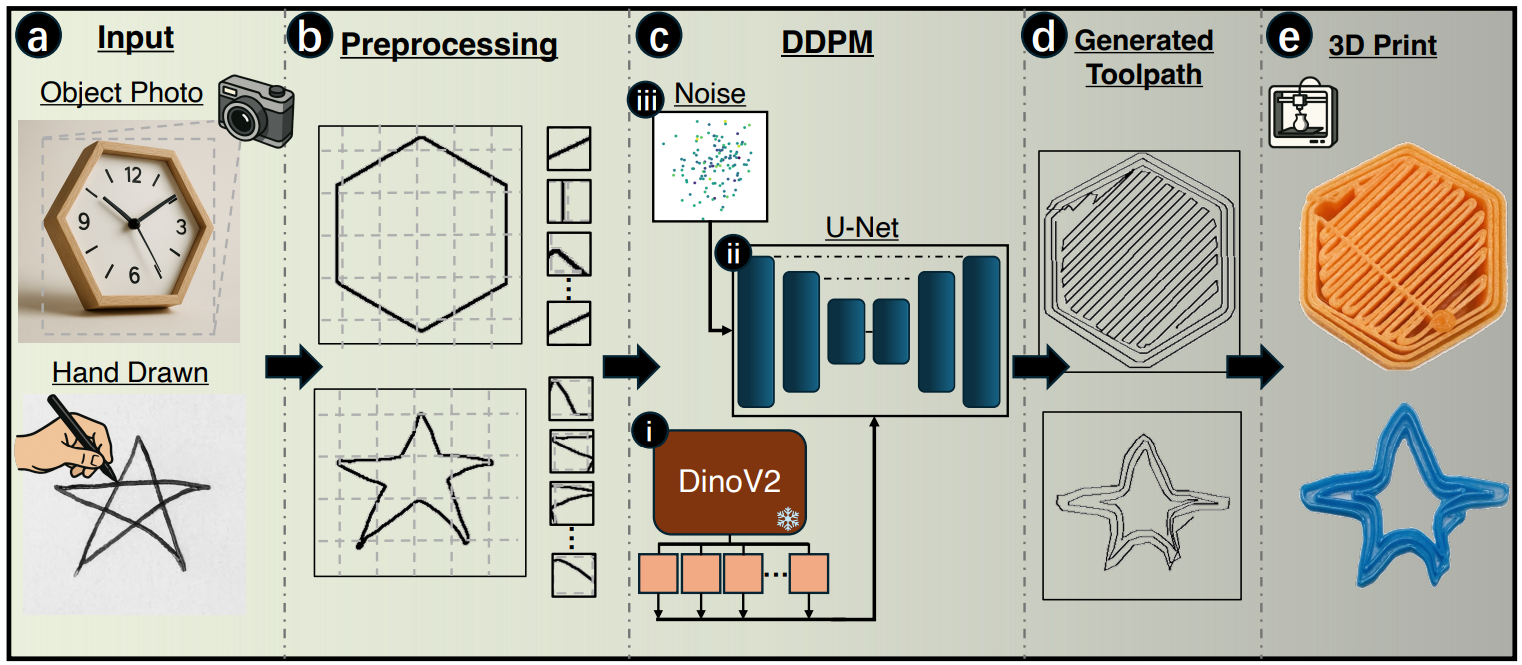
Traditional additive manufacturing workflows involve multiple steps, including CAD modeling, mesh conversion, and slicing, each requiring specialized knowledge and extensive iterations. This complexity often hinders design modification and accessibility. Image2Gcode simplifies this process by creating a direct visual-to-instruction pathway using a denoising diffusion probabilistic model (DDPM). The framework generates structured extrusion trajectories straight from an image, bypassing the need for intermediate STL and CAD files.
Users can input either hand-drawn sketches or photographs of objects. Image2Gcode effectively extracts visual features, interprets geometric boundaries, and synthesizes continuous extrusion paths. This approach not only accelerates prototyping and repair but also lowers the entry barrier for non-expert users. Researchers noted that the framework establishes a “direct and interpretable mapping from visual input to native toolpaths,” effectively bridging the gap between concept and execution in a single computational process.
Image2Gcode employs a pre-trained DinoV2-Small vision transformer, which is a self-supervised model designed for large-scale image representation learning. This is integrated with a 1D U-Net denoising architecture, conditioned through multi-scale cross-attention. The DinoV2 encoder extracts hierarchical geometric information that assists the diffusion model in generating coherent G-code. Training was conducted using the Slice-100K dataset, containing over 100,000 aligned STL–G-code pairs, allowing the model to learn the relationship between geometry and movement at the layer level.
The model was trained in PyTorch for 800 epochs using the AdamW optimizer, implementing a cosine noise schedule across 500 diffusion timesteps. This iterative denoising process produced valid, printer-ready G-code sequences, which can be adjusted without the need for retraining. Normalization across spatial and extrusion channels ensured stability and adaptability to various printer configurations.
Initial evaluations on the Slice-100K validation set indicated that Image2Gcode produced geometrically consistent and manufacturable toolpaths. Prints generated from the model’s G-code exhibited strong interlayer bonding, accurate boundaries, and smooth surfaces comparable to those produced by traditional slicer software. The toolpaths were capable of replicating complex infill structures—such as rectilinear, honeycomb, and diagonal hatching—without the need for rule-based programming.
Real-world testing extended to photographs and hand-drawn sketches, which presented data distributions distinct from the synthetic training set. Preprocessing effectively extracted shape contours from these inputs, and Image2Gcode successfully generated coherent, printable paths. The geometrically faithful and functionally sound results validated the model’s capacity to adapt pretrained DinoV2 features for real-world applications.
A quantitative analysis demonstrated a 2.4% reduction in mean travel distance compared to heuristic slicer baselines, indicating improved path efficiency without compromising print quality or mechanical strength. This suggests that the model captures geometric regularities that support optimized motion planning.
However, challenges remain. The toolpath synthesis process currently operates within a 2D slice framework and does not account for interlayer dependencies or internal cavities that require coordinated 3D path planning. The authors propose expanding the model toward hierarchical 3D generation, where a coarse global model defines key cross-sections that Image2Gcode would refine layer-by-layer. This could enhance control over fabrication outcomes by incorporating parameters for infill density, mechanical performance, and material usage.
Looking ahead, integrating Image2Gcode with AI-driven manufacturing frameworks, such as LLM-3D Print—a multi-agent system for adaptive process control and defect detection—could further extend its capabilities. By linking the diffusion model to language-based interfaces, users could specify goals—like minimizing print time or improving surface finish—that the system would translate into optimized G-code generation.
By combining diffusion-based synthesis, pretrained visual perception, and parameter normalization, Image2Gcode sets a new standard for intent-aware additive manufacturing. This data-driven architecture links design, perception, and execution, diminishing reliance on manual modeling and paving the way for fully digital workflows where sketches and photographs can be seamlessly transformed into printed components.
See also Deep Learning Model Classifies Bamboo Density with 95% Accuracy Using PyTorch
Deep Learning Model Classifies Bamboo Density with 95% Accuracy Using PyTorch AI Research Submissions Surge 200% in 2025, Raising Urgent Novelty Concerns
AI Research Submissions Surge 200% in 2025, Raising Urgent Novelty Concerns AI Systems Projected to Consume Up to 765 Billion Litres of Water Annually, Surpassing Bottled Water Use
AI Systems Projected to Consume Up to 765 Billion Litres of Water Annually, Surpassing Bottled Water Use AI Research in Cardiovascular Disease Surges 400% Since 2018, Reveals Key Trends and Insights
AI Research in Cardiovascular Disease Surges 400% Since 2018, Reveals Key Trends and Insights IIT Delhi’s AILA AI Runs Complex Lab Experiments Independently, Reducing Time by 90%
IIT Delhi’s AILA AI Runs Complex Lab Experiments Independently, Reducing Time by 90%