A recent study has highlighted a significant limitation in contemporary artificial intelligence systems, revealing that even advanced multimodal language models struggle with visual tasks that children as young as two years old can complete effortlessly. Researchers from several Chinese institutions, including UniPat AI, Peking University, and Alibaba Group, conducted the study, which introduced a benchmark called “BabyVision.” This benchmark evaluates basic visual skills that humans develop within their early months of life, such as fine-grained visual discrimination and spatial perception.
The findings are striking. Despite scoring over 90 percent on expert knowledge assessments like the Multimodal Model Understanding (MMMU), the leading AI model tested, Gemini-3-Pro-Preview, achieved only 49.7 percent on the BabyVision tasks. In stark contrast, human adults scored an average of 94.1 percent. This discrepancy underscores a troubling gap in the capabilities of existing AI technologies compared to early human cognitive development.
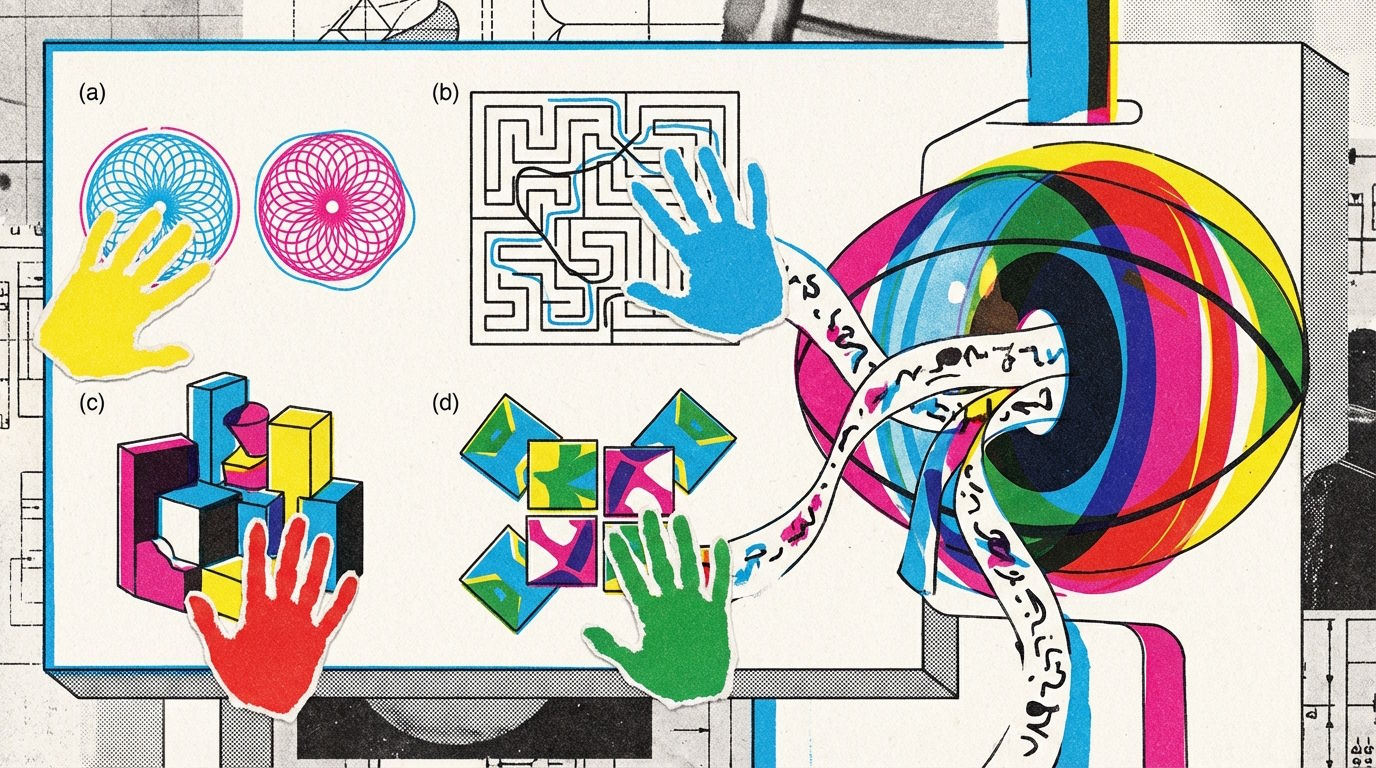
Visual perception tasks within the benchmark included recognizing subtle differences among similar patterns and tracing lines through complex mazes. One notable example involved identifying a hexagonal fragment, where Gemini-3-Pro-Preview incorrectly selected option D rather than the correct option B, primarily due to its over-reliance on verbal reasoning rather than accurate visual interpretation.
A comparison involving 80 children of varying ages revealed that most AI models underperformed relative to the average three-year-old. While Gemini-3-Pro-Preview occasionally outperformed this group, it still lagged behind typical six-year-olds by approximately 20 percentage points. Proprietary models demonstrated variable results, with GPT-5.2 following Gemini-3-Pro-Preview at 34.4 percent, and others like Claude 4.5 Opus managing a mere 14.2 percent. Open-source alternatives scored even lower, with the best performer, Qwen3VL-235B-Thinking, achieving only 22.2 percent.
The study results reveal even more concerning performance disparities on specific tasks. For instance, on counting 3D blocks, the best AI model managed only 20.5 percent, while humans scored a perfect 100 percent. In tasks requiring precise visual tracking, the majority of AI systems scored zero, highlighting their limitations in spatial reasoning.
The researchers attributed these shortcomings to what they termed the “verbalization bottleneck,” a phenomenon where multimodal models translate visual inputs into linguistic forms before processing them. This method results in the loss of critical visual information that cannot be easily described in words, particularly geometric relationships. Consequently, the BabyVision benchmark specifically targets visual characteristics that resist verbalization, exposing the limitations of current AI architectures.
To address these hurdles, the researchers developed an extension called “BabyVision-Gen,” which includes 280 additional questions requiring models to demonstrate solutions through visual means, such as drawing paths or highlighting differences. While some image generators, like Nano Banana Pro, showed potential by scoring 18.3 percent on the extended tasks, they still fell short in more complex challenges, particularly in mazes, due to current architectural constraints that hinder continuous spatial reasoning.
Looking ahead, the researchers advocate for the development of “unified multimodal models” that can process and generate visual information without succumbing to the limitations of linguistic bottlenecks. Such advancements could facilitate a more integrated approach to visual reasoning in AI. The BabyVision benchmark is publicly available on GitHub for researchers to use as a diagnostic tool to gauge progress toward achieving true visual intelligence.
Additional benchmarks, such as Francois Chollet’s ARC-AGI-3, also aim to assess basic cognitive abilities in AI, utilizing interactive mini-games designed to challenge AI agents in understanding rules autonomously. Thus far, current AI systems have scored zero points on these tasks, while human participants complete them in a matter of minutes. This ongoing exploration into visual reasoning capabilities continues to reveal the significant gap between AI and human cognitive performance.
See also Android Studio Otter Launches LLM Flexibility and Enhanced Agent Workflows for Developers
Android Studio Otter Launches LLM Flexibility and Enhanced Agent Workflows for Developers Pakistan Launches National GenAI Cyber Initiative to Boost Cybersecurity Resilience
Pakistan Launches National GenAI Cyber Initiative to Boost Cybersecurity Resilience Explainable Generative AI Study Reveals Major Gaps in Current Techniques and Standards
Explainable Generative AI Study Reveals Major Gaps in Current Techniques and Standards VSCO Launches AI Text-Prompt Tool for Mobile Photo Edits, Enhancing Creative Workflows
VSCO Launches AI Text-Prompt Tool for Mobile Photo Edits, Enhancing Creative Workflows