A study led by researchers at the University of California, Riverside (UC Riverside) has introduced a promising approach to enhance artificial intelligence (AI) systems’ ability to reason in ways similar to humans, without necessitating additional training data. The pre-print paper, titled “Test-Time Matching: Unlocking Compositional Reasoning in Multimodal Models,” presents a novel method called Test-Time Matching (TTM), which significantly improves how AI interprets relationships between text and images, especially in unfamiliar contexts.
“Compositional reasoning is about generalizing in the way humans do and understanding new combinations based on known parts,” said Yinglun Zhu, the assistant professor leading the study and a member of the Department of Electrical and Computer Engineering at the Bourns College of Engineering. “It’s essential for developing AI that can make sense of the world, not just memorize patterns.”
Current leading AI models can excel in various tasks but often struggle to align visual scenes with language when faced with altered arrangements or descriptions of familiar objects and relationships. Specialized tests are employed to evaluate whether AI models can integrate concepts as humans do; however, these models frequently perform no better than chance, indicating difficulties in grasping nuanced word-image relationships.
The research team observed that existing evaluation methods might unfairly disadvantage AI models. Current metrics predominantly rely on isolated pairwise comparisons, imposing additional constraints that can obscure the best overall match between images and captions. To rectify this, the researchers developed a new evaluation metric that identifies the best overall matching across groups of image-caption pairs, leading to improved scores and the discovery of previously unrecognized model capabilities.
Building upon this insight, the researchers created Test-Time Matching, which allows AI systems to enhance their performance incrementally without external supervision. The technique involves the AI model predicting matches between images and captions, selecting the most confident predictions, and then fine-tuning itself based on those selections. This self-improvement process mimics how humans leverage context to reason more effectively.
The effectiveness of TTM was tested on SigLIP-B16, a relatively small vision-language model designed to understand and connect visual and textual information. With TTM, SigLIP-B16 demonstrated significant improvements on compositional reasoning benchmarks, achieving or surpassing previous state-of-the-art results. Notably, in one assessment, TTM elevated SigLIP-B16’s performance on the benchmark dataset MMVP-VLM to 89.4%, outstripping GPT-4.1.
The findings suggest that test-time adaptation strategies like TTM could become increasingly vital as AI technologies permeate real-world applications, including robotics, autonomous vehicles, and healthcare—domains where systems need to swiftly adjust to new circumstances. Zhu’s research challenges the prevailing belief that larger models are always superior, urging a reevaluation of how AI systems are evaluated and utilized.
“Sometimes, the problem isn’t the model. It’s how we’re using it,” he remarked. The full paper, co-authored by UCR’s Jiancheng Zhang and Fuzhi Tang, is available on arXiv, contributing to the ongoing discourse on enhancing AI capabilities and their applications.
See also US House Panel Advances AI Overwatch Act to Control AI Chip Exports to China
US House Panel Advances AI Overwatch Act to Control AI Chip Exports to China Microsoft’s Satya Nadella Embraces AI Competition, Predicts Tech’s GDP Share Growth
Microsoft’s Satya Nadella Embraces AI Competition, Predicts Tech’s GDP Share Growth FlashLabs Launches Chroma 1.0, First Open-Source Real-Time Voice AI with 135ms Latency
FlashLabs Launches Chroma 1.0, First Open-Source Real-Time Voice AI with 135ms Latency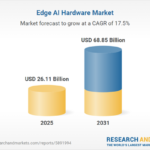 Edge AI Hardware Market to Reach $68.85 Billion by 2031, Driven by IoT Growth and AI Demand
Edge AI Hardware Market to Reach $68.85 Billion by 2031, Driven by IoT Growth and AI Demand Neurophos Raises $110 Million to Advance Exaflop-Scale Photonic AI Chips for Data Centers
Neurophos Raises $110 Million to Advance Exaflop-Scale Photonic AI Chips for Data Centers