




















































Researchers at Rutgers University and Red Hat AI Innovation, alongside the MIT-IBM Watson AI Lab, have unveiled a groundbreaking technique aimed at enhancing the efficiency of text generation through diffusion language models (DLLMs). The newly developed framework, known as Trajectory Self-Distillation with Direct Discriminative Optimization (T3D), seeks to optimize few-step decoding performance while maintaining high-quality outputs. This innovation could dramatically change how artificial intelligence generates text, making it faster and more versatile for real-world applications.
Traditional diffusion language models are characterized by their ability to generate coherent text, but they often require numerous refinement steps, which can hinder their speed. The challenge has been finding a balance between the quantity of refinement steps and the quality of the generated text. T3D addresses this by using a self-distillation process that trains the model on sequences it generates, aligning its learning with the conditions it encounters during actual text creation. This method allows for a significant reduction in refinement steps without sacrificing output quality.
The research team, led by Tunyu Zhang and Xinxi Zhang from Rutgers University, has incorporated a novel training objective called Direct Discriminative Optimization (DDO). This approach ensures the model focuses on high-probability outputs, thereby preventing the generation of overly smoothed or inaccurate text. A path-consistency regularizer further enhances the process by minimizing the impact of early errors, effectively refining the model’s performance even with limited decoding steps. These innovations enable T3D to outperform existing few-step methods, bridging the gap between speed and quality.
Extensive experiments conducted on benchmark datasets yielded promising results. For instance, using the SDAR-1.7B-Chat model on the MATH500 benchmark, T3D achieved a score of 56.80, marking an 85.02% relative increase compared to the original score of 30.66. In addition, on the GSM8K benchmark, T3D scored 78.01, representing a 12.43-point improvement over the baseline of 65.58. Under similar conditions, the SDAR-4B-Chat model with T3D reached scores of 70.00 on MATH500 and 89.31 on GSM8K, demonstrating its effective performance across various tasks.
The HumanEval benchmark also showcased T3D’s capabilities, with the SDAR-1.7B-Chat model achieving a score of 57.32, significantly up from the original model’s score of 36.10. Notably, when reverting to full diffusion decoding using static decoding with one token per step, the model maintained strong performance, achieving a score of 73.78, surpassing the original model’s 71.95. This suggests that T3D effectively preserves the generative capabilities of the diffusion models, while enhancing decoding speed.
The significance of this research lies in its potential to address a critical limitation of DLLMs: the trade-off between inference speed and generation quality. While these models can theoretically generate text in parallel, practical implementations often face bottlenecks due to the need for multiple refinement steps. T3D seeks to solve this problem by sampling pairs of clean and intermediate states from the teacher’s generated sequences, allowing the student model to learn more effectively during training.
By employing DDO, inspired by Generative Adversarial Networks, researchers have found a way to implicitly define a discriminator that guides the model towards high-probability outputs. This technique helps to mitigate the “mean-field approximation error” typical of few-step decoding, enhancing the accuracy of generated outputs. As the model’s predictions become more uncertain with fewer decoding steps, DDO encourages focus on the most promising trajectories, thereby improving overall quality.
As the demand for faster, high-quality text generation grows, the T3D framework could significantly impact various applications, from chatbots to automated content creation. This research not only highlights the ongoing efforts to enhance artificial intelligence’s capabilities but also paves the way for practical implementations that could soon bridge the gap between laboratory results and real-world applications. The full potential of diffusion models, particularly in resource-constrained environments, is now closer to realization.
👉 More information
🗞 T3D: Few-Step Diffusion Language Models via Trajectory Self-Distillation with Direct Discriminative Optimization
🧠 ArXiv: https://arxiv.org/abs/2602.12262
 Subgen AI Expands Europe Team with Key Hires to Boost AI Adoption in Sweden
Subgen AI Expands Europe Team with Key Hires to Boost AI Adoption in Sweden Researchers Discover Weight Decay Boosts LLM Adaptability, Revealing New Training Insights
Researchers Discover Weight Decay Boosts LLM Adaptability, Revealing New Training Insights India Implements Strict AI Regulations for Social Media, Mandates 3-Hour Content Removal
India Implements Strict AI Regulations for Social Media, Mandates 3-Hour Content Removal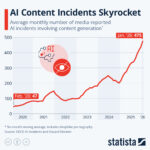 AI Content Incidents Surge to Nearly 500 Monthly by 2026, Raising Misinformation Concerns
AI Content Incidents Surge to Nearly 500 Monthly by 2026, Raising Misinformation Concerns Kling AI Launches 3.0 Suite with Enhanced Video and Image Generation Capabilities
Kling AI Launches 3.0 Suite with Enhanced Video and Image Generation Capabilities








