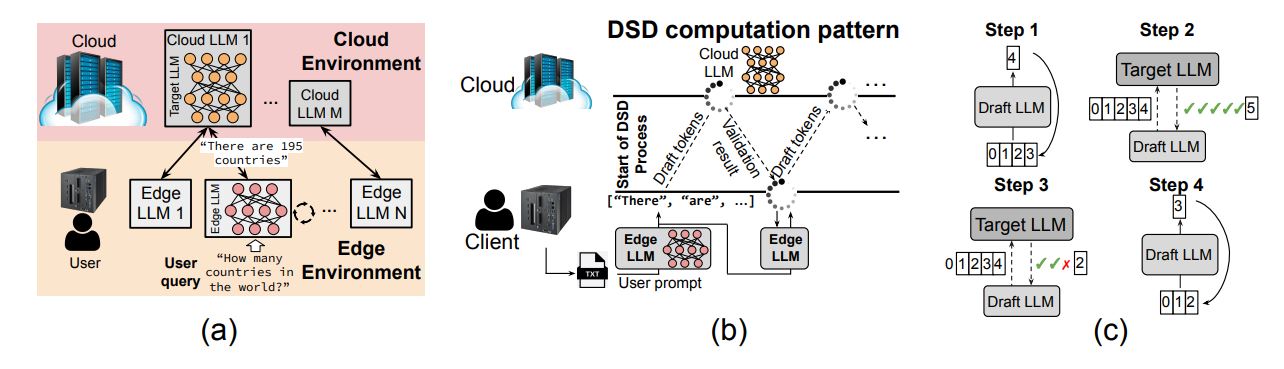
Researchers from Franklin and Marshall College and New York University have unveiled a new framework aimed at improving the processing speeds of large language model (LLM) inference across various computing environments. The framework, named Distributed Speculative Decoding (DSD), addresses the persistent challenges of slow processing and scalability when using LLMs, particularly in settings ranging from high-powered data centers to mobile devices. Led by Fengze Yu, Leshu Li, Brad McDanel, and Saiqian Zhang, this innovative approach effectively accelerates text generation by coordinating processing across multiple devices and predicting likely text sequences in advance.
In their efforts, the team recognized the need for dedicated simulation tools to optimize the distributed approach of DSD. As a solution, they developed DSD-Sim, a discrete-event simulator that accurately models the complexities of network dynamics, batching processes, and scheduling involved in multi-device LLM deployments. By simulating interactions among devices during the decoding process, DSD-Sim offers critical insights into performance bottlenecks and opportunities for optimization. The researchers also introduced an Adaptive Window Control (AWC) policy, which adjusts the size of the speculation window during inference. This data-driven method optimizes throughput by balancing the advantages of increased speculation against the risks of incorrect predictions, thereby ensuring both performance and stability.
Extensive testing confirmed the effectiveness of DSD and AWC, with results showing a performance improvement of up to a 1.1x speedup and a 9.7% increase in throughput compared to current speculative decoding methods. This enhancement significantly improves both latency and scalability, underscoring the potential of DSD to enable more responsive and agile applications of large language models in diverse environments.
The DSD framework not only accelerates LLM inference but also scales effectively across edge and cloud platforms. Traditional speculative decoding techniques are often limited to single-node execution, but DSD extends these methods to multi-device coordination, allowing for more agile and efficient LLM serving. To further simulate this distributed model, the DSD-Sim tool was employed to capture the complexities of network interactions, batching, and scheduling considerations.
Building on insights from DSD-Sim, the AWC policy leverages a Window Control Deep Neural Network (WC-DNN) that processes system state data, including queue depth, utilization rates, and round-trip time statistics. The WC-DNN predicts the optimal speculation window size through supervised regression techniques, ensuring efficient performance under varying loads. The researchers implemented measures such as clamping window size predictions, applying exponential smoothing, and introducing hysteresis for mode switching to maintain stable execution and minimize fluctuations in predicted window sizes.
The implications of this research are profound for the future of large language models. By overcoming the inherent limitations of existing methods and facilitating distributed processing, DSD represents a significant step forward in the quest for fast, scalable, and efficient AI applications. As organizations increasingly adopt LLMs for a variety of purposes—from customer service automation to content generation—the advancements made through DSD could pave the way for broader deployment and innovation in the field of artificial intelligence.
See also Synthetic Media Market Surges to $67.4B by 2034, Driven by Generative AI Innovations
Synthetic Media Market Surges to $67.4B by 2034, Driven by Generative AI Innovations OpenAI Launches GPT-5 with 10x Speed Improvement, Surpassing 1 Million Business Clients
OpenAI Launches GPT-5 with 10x Speed Improvement, Surpassing 1 Million Business Clients Gemini 3 Launches Nano Banana Pro, Revolutionizing AI Image Text Generation
Gemini 3 Launches Nano Banana Pro, Revolutionizing AI Image Text Generation Faster R-CNN by He Kaiming and Team Wins NeurIPS 2025 Test of Time Award
Faster R-CNN by He Kaiming and Team Wins NeurIPS 2025 Test of Time Award Meta Overhauls AI Content Labeling Amid Oversight Board Critique and Election Concerns
Meta Overhauls AI Content Labeling Amid Oversight Board Critique and Election Concerns