



















































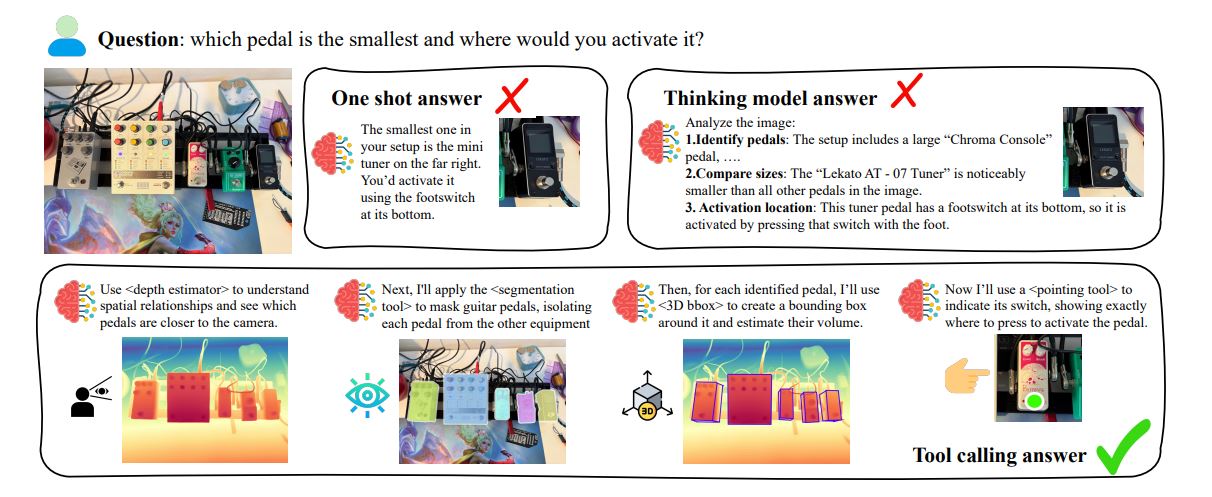
Researchers Siyi Chen, Mikaela Angelina Uy, and Chan Hee Song have developed a groundbreaking framework, called SpaceTools, aimed at enhancing the spatial reasoning capabilities of vision-language models (VLMs). Announced recently, this innovative approach addresses a critical limitation in VLMs, which have struggled with tasks requiring accurate spatial understanding and object manipulation in real-world scenarios. By leveraging a two-phase training process known as Double Interactive Reinforcement Learning (DIRL), the team enables models to utilize an array of tools, such as depth and pose estimators, thereby surpassing the constraints of pre-defined tool sequences. This advancement not only achieves state-of-the-art results on established spatial understanding benchmarks but also enhances the reliability of robotic arm manipulation, signaling a significant step forward in the field of embodied artificial intelligence.
The integration of large language models (LLMs) with specialized visual tools marks a notable evolution in robotic spatial reasoning, allowing complex tasks related to robotic manipulation to be executed with greater efficiency. The system effectively combines capabilities like object detection, depth estimation, and grasp planning, showcasing remarkable advancements in robotic intelligence. While the framework demonstrates impressive capabilities, the research team identified areas for further improvement, including the accuracy and robustness of the tools and the incorporation of real-time feedback from robots into the training process.
One of the primary breakthroughs of this research is the ability of the system to move beyond the traditional reliance on LLMs or conventional computer vision. By utilizing a suite of visual tools, the model can extract pertinent information from images and reason about spatial relationships. The interactive exploration and feedback employed in DIRL allow the model to autonomously discover optimal patterns for tool usage. This ability to coordinate multiple tools marks a substantial advancement over prior methods that relied heavily on fixed pipelines or manual prompting.
DIRL operates in two distinct phases. The initial phase focuses on teaching, wherein demonstrations from a single-tool specialist are combined with traces from a system that employs all available tools. This dual approach equips the model with a more comprehensive understanding of tool coordination. The subsequent exploration phase further refines this coordination through ongoing reinforcement learning. To manage the computational demands of this interactive training, the team introduced Toolshed, a platform that facilitates the rapid hosting of computationally intensive computer vision tools as on-demand services.
This innovative training method allows VLMs to effectively navigate the complexities of tool utilization without depending on fixed sequences or extensive manual intervention. The enhancements achieved through SpaceTools are underscored by significant performance improvements on the RoboSpatial benchmark, highlighting the superiority of DIRL compared to standard fine-tuning and baseline reinforcement learning approaches. The introduction of Toolshed also represents a noteworthy development, providing a seamless communication interface between the VLM and external resources throughout both data collection and training phases.
In practical applications, the SpaceTools system successfully controls a robotic arm, demonstrating its capacity for real-world manipulation. By coordinating tools such as depth estimators and segmentation tools, the framework learns to refine multi-tool coordination through continuous reinforcement learning. This process has yielded considerable advancements in spatial understanding benchmarks, illustrating the model’s ability to acquire complex spatial reasoning skills without necessitating major architectural changes or extensive data fine-tuning.
Despite these advancements, the research team acknowledges ongoing challenges, such as the potential for tool overuse and the misinterpretation of nuanced outputs. As the field of robotic spatial reasoning evolves, future efforts will focus on addressing these limitations to further enhance tool integration, ultimately improving the reliability and effectiveness of spatial reasoning in complex environments. This research signals a promising future for VLMs and their applications in robotics, with the potential to redefine capabilities in areas requiring nuanced spatial understanding and interaction.
See also ECI Software Solutions Launches Payments Division and AI Tools, Boosting SMB Cash Flow
ECI Software Solutions Launches Payments Division and AI Tools, Boosting SMB Cash Flow Microsoft Unveils AI Tools to Drive $1B Digital Transformation in Philippines
Microsoft Unveils AI Tools to Drive $1B Digital Transformation in Philippines Country Music Producers Embrace AI Tools Like Suno for Fast, Cost-Effective Hit Creation
Country Music Producers Embrace AI Tools Like Suno for Fast, Cost-Effective Hit Creation Google Cloud Launches Vertex AI Enhancements, Boosting Retail AI Efficiency by 36x
Google Cloud Launches Vertex AI Enhancements, Boosting Retail AI Efficiency by 36x




