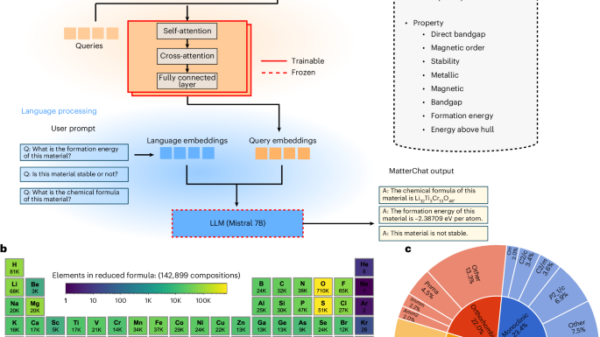
As organizations increasingly adopt Retrieval-Augmented Generation (RAG) architectures and agent-driven AI systems, a significant performance challenge has emerged: poor data serialization consumes between 40% and 70% of available tokens due to unnecessary formatting overhead. This inefficiency not only inflates API costs but also diminishes effective context windows and degrades model performance. While this issue may go unnoticed during pilot phases with limited data, it becomes critical at scale. An inefficiently serialized record can waste hundreds of tokens, and when accumulated across millions of queries, the financial implications are steep, often determining the viability of AI deployments.
Token consumption in large language model (LLM) applications is typically categorized into several areas, with serialization overhead presenting one of the most substantial opportunities for optimization. Understanding how tokenization impacts AI implementation is essential, as it directly influences model performance and costs. For instance, a standard enterprise query requiring context from multiple data sources—historical records, entity metadata, behavioral patterns, and real-time signals—could consume between 3,000 and 4,000 tokens when using JSON serialization. In an 8,192-token context window, this allocation leaves limited space for actual analysis, posing a major obstacle for applications needing deeper context or multi-turn conversations.
Much of this overhead can be attributed to structural formatting, which consumes tokens without providing useful information for the model. To mitigate these challenges, organizations can adopt three core optimization strategies. First, eliminating structural redundancy is crucial; while JSON’s verbosity enhances human readability, it is token-inefficient. Employing schema-aware formats can significantly reduce repetitive structure. Second, optimizing numerical precision can lower token consumption by 30% to 40%. Most LLMs do not require millisecond-level precision for analytical tasks, and precision-aware formatting can streamline data representation. Commonly, business applications function effectively with two decimal places for currency, minute-level precision for timestamps, and one to three decimal places for coordinates.
Lastly, applying hierarchical flattening can drastically reduce token usage. Nested JSON structures introduce significant overhead, and flattening these hierarchies to include only essential fields can lead to a 69% reduction in token consumption. A systematic approach should be adopted to analyze which fields are truly necessary for queries, removing redundant identifiers and highly nested structures that do not influence model outputs.
Building a Preprocessing Pipeline
The establishment of an effective preprocessing pipeline is vital as organizations scale RAG systems. A well-designed data preparation layer can enhance efficiency, especially when dealing with vast document corpora that cannot be directly input into an LLM. Key components of this pipeline include schema detection to automatically identify data types and structures, compression rules tailored to data types, deduplication to eliminate repeated structures, and continuous token counting to monitor and enforce token budgets. Validation processes are essential to ensure that compressed data retains its semantic integrity.
Organizations that implement these optimization strategies typically observe context size reductions of 60% to 70%, leading to a two to three times increase in effective context capacity and a proportional decrease in per-query token costs. Performance metrics also show maintained or improved accuracy through A/B testing, reduced query latency, and the elimination of context window exhaustion. The financial implications are significant, as organizations can achieve substantial reductions in API costs while simultaneously increasing their processing capacity without additional infrastructure investment.
As AI spending continues to strain enterprise budgets, addressing token waste becomes a strategic priority. The economic ramifications compound quickly at scale; for example, 1,000 wasted tokens per query across 10 million daily queries can amount to a $20,000 daily waste, yielding an annual cost of $7.3 million. Thus, token optimization is not merely about cutting costs but also about enhancing capabilities, allowing for better model performance at reduced expenses.
To initiate these optimizations, organizations should begin by assessing their current token usage, as many discover that 40% to 60% of their serialization approaches are wasteful. By measuring token consumption throughout their data pipelines and identifying high-impact optimization opportunities, companies can implement changes incrementally, validating each step. The most accessible improvements in LLM optimization are often found not within the model itself but in the data preparation processes that feed it.
See also Google Launches Veo 3.1 AI Video Tool, Surpassing OpenAI in Realism and Control
Google Launches Veo 3.1 AI Video Tool, Surpassing OpenAI in Realism and Control