






























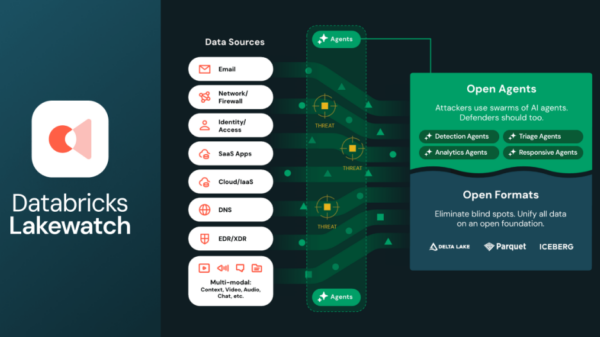










Google Research has introduced a new compression algorithm called TurboQuant, designed to significantly reduce the memory requirements of large language models (LLMs) while enhancing their speed and accuracy. Amidst escalating demand for memory resources in generative AI, this development comes as a relief to users grappling with high costs associated with random access memory (RAM). TurboQuant addresses the need for efficient memory usage, particularly in the key-value cache, a critical component that retains essential information for LLMs.
The key-value cache functions similarly to a “digital cheat sheet,” storing vital data to prevent the need for repetitive computations. As LLMs are fundamentally incapable of “knowing” information, they rely on vectors to represent semantic meaning. These vectors allow the model to perform its tasks by mapping tokenized text into a conceptual space. However, the high-dimensional vectors, which can contain hundreds or thousands of embeddings, consume substantial memory and can slow down performance due to their size.
To combat this issue, developers often resort to quantization techniques that enable the models to operate with lower precision, thus reducing their footprint. However, this typically comes with a trade-off in the quality of outputs, as the accuracy of token estimates diminishes. In contrast, early tests of TurboQuant have indicated an impressive 8x performance increase and a 6x reduction in memory usage, all without compromising output quality.
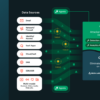
Implementing TurboQuant involves a two-phase process. The foundation of its effectiveness lies in a method called PolarQuant. Traditionally, AI model vectors are encoded using standard XYZ coordinates; however, PolarQuant shifts this representation into polar coordinates within a Cartesian framework. This adjustment allows vectors to be distilled into two critical pieces of information: a radius indicating core data strength and a direction that conveys the meaning of the data.
The implications of TurboQuant are significant, especially as the demand for AI applications surges across various sectors, from tech to healthcare. By enhancing the efficiency of LLMs, Google is not only facilitating cost-effective computing solutions but also enabling developers to create more robust applications. As the landscape of artificial intelligence continues to evolve, innovations like TurboQuant could redefine the capabilities and accessibility of generative AI technologies.
See also Sam Altman Praises ChatGPT for Improved Em Dash Handling
Sam Altman Praises ChatGPT for Improved Em Dash Handling AI Country Song Fails to Top Billboard Chart Amid Viral Buzz
AI Country Song Fails to Top Billboard Chart Amid Viral Buzz GPT-5.1 and Claude 4.5 Sonnet Personality Showdown: A Comprehensive Test
GPT-5.1 and Claude 4.5 Sonnet Personality Showdown: A Comprehensive Test Rethink Your Presentations with OnlyOffice: A Free PowerPoint Alternative
Rethink Your Presentations with OnlyOffice: A Free PowerPoint Alternative OpenAI Enhances ChatGPT with Em-Dash Personalization Feature
OpenAI Enhances ChatGPT with Em-Dash Personalization Feature