











































March 25, 2026 – GoodVision AI, an AI infrastructure firm helmed by former AWS and IBM executives, has unveiled an intelligent compute scheduling solution integrated with a distributed edge inference infrastructure. This offering is designed to tackle challenges associated with rising token consumption, latency, and costs that have emerged from the swift adoption of AI agents.
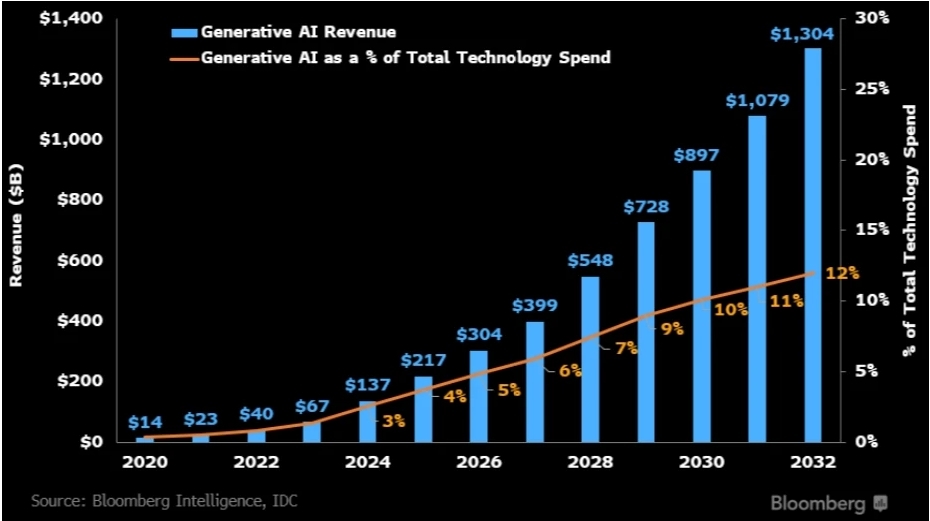
At the GTC 2026 event, NVIDIA CEO Jensen Huang highlighted the transformation of AI infrastructure from traditional “data centers” to “token factories,” where inference throughput is becoming a critical metric. Huang indicated that the demand for inference could escalate dramatically, potentially increasing by a million-fold within the next two years.
Concurrently, systems such as OpenClaw are representing a new category of AI agents capable of understanding user intent and executing multi-step tasks across workflows. As these systems are deployed in production settings, a new constraint around token consumption is becoming evident.
For instance, a single intricate task performed by an AI agent may necessitate hundreds of model calls, amplifying token usage when compared to traditional prompt-response interactions. Industry professionals report that agent-based workflows can lead to significant increases in token expenditure, with some scenarios witnessing extremely high daily consumption levels.
Hyperscale cloud providers are ramping up their capital expenditures to expand AI infrastructure, with planned investments surpassing $280 billion in 2026, primarily focused on securing power resources and compute capacity for the coming years.
However, the rapid rise in demand poses a critical question for the industry: can merely scaling centralized compute infrastructure effectively address the efficiency, cost, and latency issues associated with real-world AI deployments?
GoodVision AI’s CEO, David Wang, who has extensive experience in the cloud computing landscape, argues that the consistent pattern he observed—where application demand outpaces compute infrastructure supply—was a key motivation behind founding GoodVision AI in 2019. This discrepancy between supply and demand has only intensified as large models and AI applications have proliferated. In 2025, the company saw its AI-related revenue soar to nearly $10 million, with over 100% year-over-year growth.
Wang emphasizes that AI infrastructure must shift toward a more distributed and hierarchical architecture. He proposes that centralized cloud models handle complex tasks, while edge or localized compute should manage high-frequency, latency-sensitive inference tasks.
The primary goal is not simply to increase compute resources, but rather to improve the allocation of those resources. An intelligent scheduling system enables dynamic routing of tasks based on their complexity, effectively preventing bottlenecks in centralized hyperscale data centers and enhancing real-time performance.
As AI agents gain prominence, a new class of demand is emerging where agent-driven workflows require coordination across various models and compute types. If all inference requests are routed to remote centralized data centers, both latency and costs can spiral out of control.
GoodVision AI aims to address this challenge by developing an intelligent compute distribution network, akin to a Content Delivery Network (CDN) that emerged in the early days of the internet. Rather than a single centralized server, this network facilitates the distribution of computing resources across a wide geographic area, bringing processing closer to end users and reducing latency.
The company’s architecture, referred to internally as the AI Factory, combines GPU compute resources with a globally distributed compute node network and an intelligent scheduling layer. This enables efficient workload orchestration across heterogeneous environments.
One of GoodVision AI’s notable innovations is its token-level compute scheduling, which allocates workloads based on a task’s specific requirements rather than at a model level. This approach allows for intelligent routing of workloads across both public cloud platforms and private data centers, thus optimizing execution paths in real time.
GoodVision AI is expanding its inference compute footprint globally. With over 400 megawatts of power capacity secured across regions such as Japan, South Korea, and the United States, the company plans to establish substantial production-grade inference clusters capable of supporting up to 400,000 inference GPUs.
As AI agents become more integrated into daily workflows, the demand for compute is expected to grow exponentially. The evolution towards a globally distributed network of compute nodes is foundational to GoodVision AI’s vision. Each AI Factory aims to serve regional AI applications while remaining interconnected within a global compute network.
The result is a more efficient system that enables real-time inference processing at the city level, significantly improving performance metrics for clients, including cost reductions and lower latency. As industries such as biotech increasingly depend on AI, they are poised to become key customers for GoodVision AI’s compute network.
Looking forward, as cities develop their own AI Factories, compute resources are set to transform into a utility, making AI agents accessible to developers, enterprises, and individual users alike, thus paving the way for widespread AI adoption.
See also Affordable Android Smartwatches That Offer Great Value and Features
Affordable Android Smartwatches That Offer Great Value and Features Russia”s AIDOL Robot Stumbles During Debut in Moscow
Russia”s AIDOL Robot Stumbles During Debut in Moscow AI Technology Revolutionizes Meat Processing at Cargill Slaughterhouse
AI Technology Revolutionizes Meat Processing at Cargill Slaughterhouse Seagate Unveils Exos 4U100: 3.2PB AI-Ready Storage with Advanced HAMR Tech
Seagate Unveils Exos 4U100: 3.2PB AI-Ready Storage with Advanced HAMR Tech
















