










































Spanish startup Multiverse Computing has unveiled the HyperNova 60B 2602, a free, compressed large language model designed to provide near-frontier performance while significantly reducing resource requirements. Available to developers on Hugging Face, this release aims to democratize access to advanced AI capabilities for enterprises facing challenges related to hardware, latency, and costs.
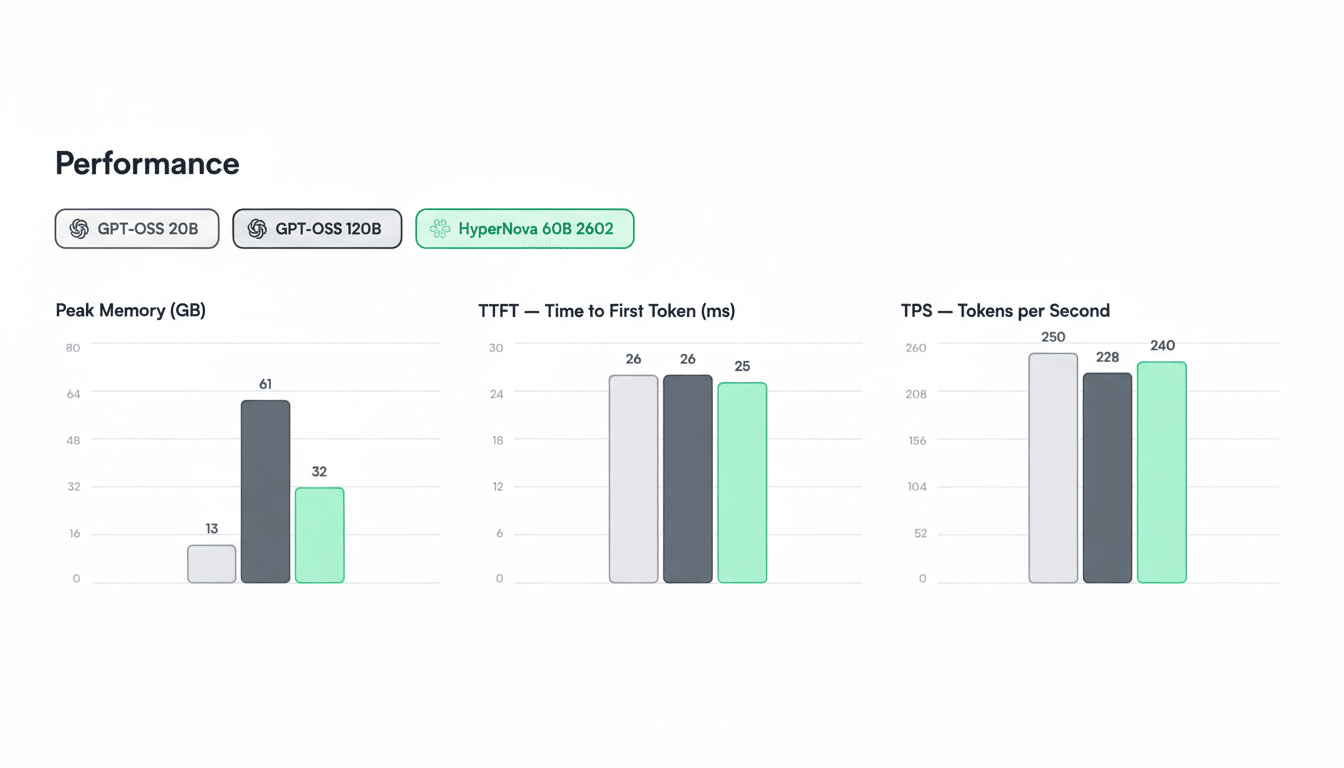
The HyperNova 60B is a compressed variant of OpenAI’s gpt-oss-120B, employing Multiverse’s proprietary CompactifAI technology. The new model has a memory footprint of approximately 32GB—roughly half that of its source model—while offering enhanced memory efficiency and reduced latency during inference. The latest upgrade, 2602, includes improvements in tool calling and agentic coding, addressing high-cost workloads that typically burden traditional models.
Multiverse plans to release additional compressed models throughout the year to cover a broad range of tasks including code synthesis, retrieval-augmented generation, and structured extraction. Currently, the availability of HyperNova 60B offers AI engineers a platform for testing the viability of compressed models in delivering production-grade accuracy without incurring the typical overhead associated with conventional infrastructures.
Model compression is a crucial innovation aimed at maintaining accuracy while drastically reducing computational and memory requirements. Techniques such as pruning, knowledge distillation, and quantization are prevalent in the industry; however, CompactifAI introduces a quantum-inspired approach to parameter reduction and representation. The practical result is that a model of this scale can operate on a single high-memory GPU or a modest multi-GPU server, leading to substantial decreases in operational and capital expenditures for on-premises and edge deployments.
For businesses, the financial implications of model compression are compelling. Inference costs frequently represent the largest share of AI expenses at scale, particularly for tasks involving long-context reasoning, tool utilization, and code generation. A smaller model can yield higher tokens-per-second rates, require fewer nodes to meet latency service-level agreements, and improve resource utilization—all crucial metrics that CFOs and platform teams monitor alongside accuracy. Analysts from organizations such as MLCommons and Stanford’s Center for Research on Foundation Models emphasize that improvements in throughput and latency are as critical as traditional benchmark scores when models are deployed in real-world settings.
Multiverse claims that HyperNova 60B outperforms the Mistral Large 3 on specific tasks while approaching the accuracy levels of much larger models. However, independent evaluations will be essential to substantiate these claims. Anticipate rigorous testing across established benchmarks like MMLU, GSM8K, and HumanEval to assess how effectively a compressed 60B-class model competes against its uncompressed counterparts in practical applications.
This strategic positioning aligns with a broader European initiative for high-performance, sovereign AI solutions. While Mistral AI has gained traction with compact, capable systems, Multiverse aims to capture the market for compressed, enterprise-friendly models that can operate locally, thereby ensuring compliance with data residency and governance regulations—a priority underscored by European and Canadian regulators.
Founded in the Basque Country and now active across Europe and North America, Multiverse counts major enterprises like Iberdrola, Bosch, and the Bank of Canada among its clients. The company raised $215 million in a Series B funding round last year, backed by Spain’s Agency for Technological Transformation, and has since entered a collaboration with the regional government of Aragón. This support from local institutions highlights an initiative to foster domestic AI technologies rather than solely depend on U.S.-based providers.
While revenue from Multiverse would represent a fraction of OpenAI’s estimated $20 billion annual revenue, it is aligned with the increasing demand for alternatives to U.S. offerings, which helped propel Mistral to over $400 million in annual revenue. The company’s focus on compression could serve as a strategic entry point into this expanding market, enabling it to meet accuracy demands while lowering total ownership costs for regulated industries that favor on-premises or sovereign cloud deployments.
As developers now have free access to test HyperNova 60B, they can benchmark its latency, memory usage, and tool-calling reliability against their existing frameworks. Key areas for diligence will include compliance with licensing requirements for the base model, reproducibility of Multiverse’s compression techniques, and transparency in evaluation reports. Third-party assessments and red-teaming will be critical if the model is to be deployed in domains where safety is paramount.
If the performance claims hold true, compressed foundation models like HyperNova 60B may become the preferred choice for enterprises requiring robust reasoning capabilities without incurring the high costs associated with frontier computational resources. In a landscape increasingly driven by throughput, cost-per-token, and data sovereignty, Multiverse’s introduction of this model presents a timely exploration of whether smaller models can effectively compete at scale.
See also Vector-Borne Disease Surveillance AI Market to Reach $4.01 Billion by 2030 with 20.2% CAGR
Vector-Borne Disease Surveillance AI Market to Reach $4.01 Billion by 2030 with 20.2% CAGR TD SYNNEX Partners with SCAILIUM for AI Infrastructure, Boosting Growth Potential
TD SYNNEX Partners with SCAILIUM for AI Infrastructure, Boosting Growth Potential SambaNova Secures $350M and Partners with Intel to Develop Next-Gen AI Chips
SambaNova Secures $350M and Partners with Intel to Develop Next-Gen AI Chips India Invests in Mathematics to Fuel AI and Quantum Computing Growth
India Invests in Mathematics to Fuel AI and Quantum Computing Growth VAST Data Launches PolicyEngine and TuningEngine for Secure, Adaptive AI Systems
VAST Data Launches PolicyEngine and TuningEngine for Secure, Adaptive AI Systems

















