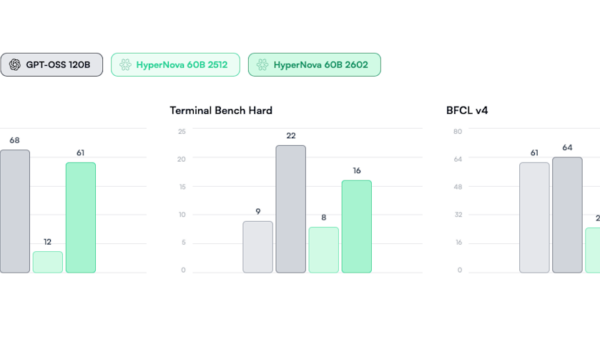















































Researchers are increasingly turning to multiomics to gain a comprehensive understanding of human biology, yet its clinical application remains limited. Multiomics integrates various biological layers—genomics, transcriptomics, proteomics, and metabolomics—offering a holistic view crucial for deciphering disease mechanisms and advancing drug design. However, issues surrounding data fragmentation hinder its potential.
At a recent event, Prof. Namshik Han, a leading figure in AI research at CardiaTec Biosciences and head of the Quantum Information department at Yonsei University, highlighted the challenges of piecing together multiomics data from disparate sources. He noted that integrating gene expression data from one cohort in the U.S., DNA sequencing from another in Africa, and epigenetic data from Japan complicates reliable data synthesis, thereby obstructing effective drug discovery.
To address these challenges, Han and his team are focused on creating a high-quality, unbiased multiomics database specifically for human cardiac tissue. “What we have set out to do is generate multiomics data from the same tissue in a single patient,” Han explained, emphasizing the importance of consistency for robust insights.
Moreover, the use of AI is central to interpreting the extensive data generated through multiomics. Han elaborated that conventional statistical methods fail to adequately unpack the complexities inherent in multiomics datasets. Instead, his lab employs graph-based AI algorithms, transforming multiomics data into a three-dimensional structure for deeper analysis.
AI’s integration with multiomics marks a transformative approach in drug discovery, enabling developers to model drug-disease interactions and predict efficacy and toxicity before clinical trials. This synergy is particularly promising for personalized medicine, where deep learning models could analyze multiomics data to forecast individualized drug responses. However, Han cautioned that training AI models on population-based data is essential to contextualize these predictions.
Quality data is paramount for the success of AI applications in multiomics. “AI models require a large amount of data for training. Even more importantly, it requires high-quality data; without it, predictive results will be poor,” Han stated. Fragmented or inconsistent data often lead to failed AI applications that fail to generate meaningful insights.
The resolution to the fragmentation issue lies in developing next-generation multiomics platforms capable of capturing diverse data types from a single sample during one experimental run. This advancement, alongside computational frameworks that can seamlessly integrate multi-modal data, is crucial for the future of drug discovery.
Integrated multiomics is already yielding insights into diseases that could not be discerned through single-modality analysis. For instance, researchers have successfully combined genomic, transcriptomic, and proteomic data to uncover distinct molecular subtypes of pancreatic cancer within endometrial carcinomas.
When enhanced by AI, integrated multiomics can transition from merely identifying patterns to uncovering unexpected correlations, enabling new hypotheses to be tested in vitro. This transformative capability positions AI as an indispensable tool for advancing biological research.
Education is Key to Unlocking AI’s Potential
However, realizing the full potential of AI in multiomics extends beyond technological advancements; it necessitates a blend of biological and computational expertise. Han pointed out, “The biggest hurdle is not developing an AI algorithm but having a biological understanding of the multiomics data, because without that, we cannot create a functional algorithm.” The ideal scenario involves researchers with both biological and computer science knowledge to effectively analyze and interpret the data.
The current lack of AI expertise within the healthcare sector can be attributed to competitive tech industry dynamics, as many computer science graduates are drawn to higher-paying roles outside of healthcare. Nonetheless, Han noted a promising trend where students are increasingly recognizing the value of AI in drug discovery and are opting for related paths. “What we can do is educate young students to become the next generation of AI healthcare researchers,” he concluded.
By merging multiomics with AI, researchers stand to reveal intricate patterns in high-dimensional datasets that are beyond human capabilities. This collaboration signifies a shift from static snapshots of biological systems to dynamic models of disease, accelerating the discovery of transformative therapies. The essential components for success in this new paradigm will be consistent, scalable data and a workforce equipped with both biological and computational insights.
For more information on multiomics and the role of AI in drug discovery, visit CardiaTec Biosciences, or explore the latest research at Yonsei University.
See also AI Impact Summit 2026: India Leads Global Dialogue on Workforce Reskilling Amid AI Automation
AI Impact Summit 2026: India Leads Global Dialogue on Workforce Reskilling Amid AI Automation Yann LeCun Critiques Alexandr Wang’s Leadership at Meta, Calls for AI Research Reforms
Yann LeCun Critiques Alexandr Wang’s Leadership at Meta, Calls for AI Research Reforms Meta Invests $2B in AI Startup Manus Amid Shareholder Concerns and Insider Sales
Meta Invests $2B in AI Startup Manus Amid Shareholder Concerns and Insider Sales El Salvador Commits $XXX Million to Bitcoin and AI Investments Through 2026
El Salvador Commits $XXX Million to Bitcoin and AI Investments Through 2026 China’s AI Surge: DeepSeek Models Challenge US Dominance, Targeting 2027 Leadership
China’s AI Surge: DeepSeek Models Challenge US Dominance, Targeting 2027 Leadership














