




















































Epoch AI’s analysis reveals that benchmarks designed to measure AI model performance are heavily influenced by the methods used for testing, complicating evaluations of these systems. The research organization has identified numerous hidden variables that can significantly alter outcomes, suggesting that the reliability of benchmark results may not be as solid as previously believed.
Epoch AI divides the sources of variability into two categories: benchmark setup, which encompasses how the test is conducted, and model access, which pertains to how the AI model is invoked. According to their findings, both areas present considerable flexibility that can skew final scores, raising questions about the validity of benchmarks across different implementations.
Even established tests, such as GPQA-Diamond, exhibit discrepancies among different implementations. The researchers analyzed four popular benchmark libraries and noted that variations in prompt formulations and temperature settings lead to different performance outcomes. For instance, EleutherAI operates at a temperature of 0.0, while OpenAI’s simple-evals uses 0.5, and OpenAI’s gpt-oss defaults to 1.0. This variation can lead to a performance disparity of between 74 and 80 percent for the same model, contingent on the configuration used.
The disparity becomes even more pronounced with complex benchmarks like SWE-bench Verified. Here, the “scaffold”—the software that controls the AI agent—plays a pivotal role, with Epoch AI reporting that merely switching scaffolds can result in a performance variation of up to 11 percentage points for GPT-5 and 15 percentage points for Kimi K2 Thinking. The researchers assert that scaffold choice has the “single biggest impact” on overall performance metrics.
A critical factor contributing to the variability in assessment scores is the choice of API provider. Epoch AI’s testing revealed that different providers yield widely varying results for the same model. For example, while models like GLM-4.6 demonstrated accuracy rates of around 80 percent with some providers like Together and Fireworks, others, such as Mancer and AtlasCloud, fell below the 40 percent mark. Causes for these discrepancies include rate limits, incomplete responses, and incorrect parameter transmissions. MiniMax noted a staggering 23 percentage point difference in tau-bench results when comparing its API implementation with standard interfaces.
The analysis highlights that newer models, such as GLM-4.6, often perform worse than established models like Qwen3, complicating evaluations right after release when interest is typically at its peak.
Execution environments also pose challenges. Epoch AI pointed out that OpenAI was only able to run 477 out of 500 SWE-bench problems due to “infrastructure challenges.” Test environments can harbor critical bugs that allow AI agents to “hack the eval,” leading to misleading results. In particular, evaluations that provide agents with web access are especially vulnerable, as agents could exploit the original datasets or publicly available resources.
A recent incident involving the coding model IQuest-Coder illustrates these pitfalls. The model, equipped with 40 billion parameters, outperformed much larger competitors in SWE-bench tests. However, it was later discovered that the test environment was misconfigured and contained the complete Git history, allowing the model to read existing solutions rather than solve problems independently. Despite these methodological flaws, IQuest-Coder garnered significant attention shortly after its release, demonstrating how quickly benchmark results can gain traction before their reliability is scrutinized.
The concerns surrounding AI benchmarks are not novel. Previous studies have indicated that OpenAI’s o1 achieved inconsistent results in programming tests based on the framework used. Moreover, a comprehensive review of 445 benchmark papers uncovered fundamental methodological deficiencies, with most benchmarks exhibiting flaws in definitions, task selection, or statistical analysis.
Epoch AI’s researchers caution that myriad small variables accumulate across the entire evaluation process, leading to significant deviations from reported model performance. These inconsistencies present challenges for evaluators, who face laborious and costly efforts to replicate known results. Furthermore, transparency issues extend to benchmark funding; OpenAI was found to have secretly financed the development of Epoch AI’s major math benchmark, FrontierMath.
As the complexity of AI systems continues to evolve, the reliability of benchmarks remains a critical concern for developers and evaluators alike, highlighting the need for increased transparency and rigor in the benchmarking process.
See also AI Memorization Crisis: Stanford Reveals Major Copyright Risks in OpenAI, Claude, and Others
AI Memorization Crisis: Stanford Reveals Major Copyright Risks in OpenAI, Claude, and Others Researchers Develop Physics-Informed Deep Learning Model for Accurate Rainfall Forecasting
Researchers Develop Physics-Informed Deep Learning Model for Accurate Rainfall Forecasting Automated Machine Learning Improves Frailty Index Accuracy for Spinal Surgery Outcomes
Automated Machine Learning Improves Frailty Index Accuracy for Spinal Surgery Outcomes LG’s K-Exaone Achieves 7th Place in Global AI Rankings, Dominating Benchmark Tests
LG’s K-Exaone Achieves 7th Place in Global AI Rankings, Dominating Benchmark Tests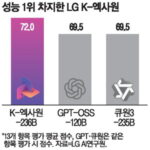 LG AI Research Institute Achieves Top Scores in National AI Model Benchmark Tests
LG AI Research Institute Achieves Top Scores in National AI Model Benchmark Tests










