












































Researchers at Stanford and Yale have exposed a significant concern for the generative AI industry, revealing that four widely used large language models—OpenAI’s GPT, Anthropic’s Claude, Google’s Gemini, and xAI’s Grok—are capable of memorizing and reproducing extensive excerpts from the texts they were trained on. This finding challenges previous assertions made by AI companies that their models do not retain copies of proprietary content.
During their research, the team prompted these models strategically, resulting in Claude delivering nearly complete texts from classics such as Harry Potter and the Sorcerer’s Stone, The Great Gatsby, 1984, and Frankenstein, among others. Thirteen books were tested, and varying amounts of content were reproduced by each of the models.
This phenomenon, referred to as “memorization,” has long been dismissed by AI firms. In a 2023 letter to the U.S. Copyright Office, OpenAI stated, “models do not store copies of the information that they learn from.” Similarly, Google claimed there exists “no copy of the training data—whether text, images, or other formats—present in the model itself.” Other major players like Anthropic, Meta, and Microsoft echoed these sentiments. However, the latest study contradicts these claims, providing evidence of copied content within AI models.
The implications of this discovery could be profound, potentially exposing AI companies to massive legal liabilities that may cost billions in copyright infringement judgments. Furthermore, the findings challenge the prevailing narrative in the AI sector that likens machine learning to human cognitive processes. Instead, researchers argue that AI models do not learn in the traditional sense. Rather, they store and retrieve information, often through a process described as lossy compression.
This technical term gained traction recently when a German court ruled against OpenAI after finding that ChatGPT could produce close imitations of song lyrics. In this context, the judge compared AI models to formats like MP3 and JPEG, which compress files while retaining some degree of the original data. This suggests that while AI models store information, the output may not be exact replicas, but approximations of original texts.
The challenge of defining how AI models handle their training data is evident in image generators as well. In September 2022, Emad Mostaque, co-founder and then-CEO of Stability AI, explained how their model, Stable Diffusion, compresses vast amounts of image data into a manageable format capable of recreating visuals from its training set. A researcher familiar with this model demonstrated its ability to reproduce near-exact copies of images, indicating that these models can retain certain visual attributes from their sources.
Additionally, the research highlights that AI models often do not simply learn broad concepts from their training data but can output text and images closely resembling the originals. For example, Google stated that LLMs store “patterns in human language,” a notion that can mislead when considering the models’ capabilities. When processed, the text is broken into tokens—smaller parts—that can recreate exact phrases from the original material, thus making it possible for models to regurgitate significant sections of copyrighted content.
In one instance, a study indicated that Meta’s Llama 3.1-70B model could produce the entirety of Harry Potter and the Sorcerer’s Stone from just a few initial tokens. Other works, like A Game of Thrones and Beloved, have also been identified as potentially reproducible with minimal prompting.
As the AI industry grapples with these findings, the legal implications of memorization are significant. If AI developers cannot prevent models from producing memorized content, they may face lawsuits requiring them to remove infringing products from the market. Moreover, if courts determine that models constitute illegal copies of copyrighted works, companies may be mandated to retrain their models using properly licensed data.
A recent lawsuit from The New York Times alleged that OpenAI’s GPT-4 could reproduce numerous articles nearly verbatim. In response, OpenAI argued that the Times utilized “deceptive prompts” in violation of the company’s terms of service. The company characterized such reproductions as “a rare bug” they are working to resolve.
However, ongoing research suggests that the inherent ability to plagiarize is not an isolated issue but rather a fundamental characteristic of major LLMs. Experts assert that this phenomenon of memorization is widespread and unlikely to be eradicated. As OpenAI CEO Sam Altman continues to advocate for the technology’s right to learn, it raises questions about the ethical implications of utilizing creative works without explicit consent or licensing. This dialogue is vital as the industry evolves, and stakeholders must confront the legal, ethical, and societal ramifications of AI’s relationship with intellectual property.
See also Researchers Develop Physics-Informed Deep Learning Model for Accurate Rainfall Forecasting
Researchers Develop Physics-Informed Deep Learning Model for Accurate Rainfall Forecasting Automated Machine Learning Improves Frailty Index Accuracy for Spinal Surgery Outcomes
Automated Machine Learning Improves Frailty Index Accuracy for Spinal Surgery Outcomes LG’s K-Exaone Achieves 7th Place in Global AI Rankings, Dominating Benchmark Tests
LG’s K-Exaone Achieves 7th Place in Global AI Rankings, Dominating Benchmark Tests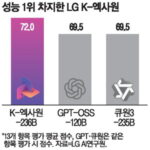 LG AI Research Institute Achieves Top Scores in National AI Model Benchmark Tests
LG AI Research Institute Achieves Top Scores in National AI Model Benchmark Tests AI Expert Nathan Lambert Reveals Multi-Model Strategy for Optimal Performance
AI Expert Nathan Lambert Reveals Multi-Model Strategy for Optimal Performance