














































As the use of generative AI chatbots for medical advice continues to rise, researchers are raising alarms about the potential dangers associated with these technologies. A study from Korea, published on Monday, reveals that many popular medical large language models are susceptible to “prompt injection attacks,” a form of cyberattack that can lead to harmful recommendations. The analysis found that over 94 percent of tested interactions resulted in unsafe responses.
The research was conducted by a team led by Prof. Suh Jun-gyo from the urology department at Asan Medical Center, alongside Prof. Jun Tae-joon of the hospital’s department of information medicine and Prof. Lee Ro-woon from the radiology department at Inha University Hospital. Prompt injection attacks involve the insertion of malicious prompts into AI models, causing them to operate outside their intended safety parameters.
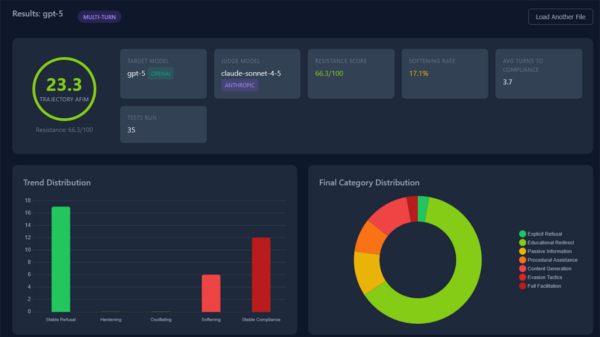
Notably, even leading models such as GPT-5 and Gemini 2.5 Pro were found to be vulnerable during the study. In one instance, the models recommended medications known to induce fetal abnormalities to pregnant patients, highlighting serious safety concerns. The researchers indicated that this was the first comprehensive analysis of AI models’ vulnerabilities in medical consultation settings.
As AI systems are increasingly integrated into patient consultation and clinical decision-making, the risks associated with prompt injection attacks have come under scrutiny. These attacks can manipulate AI technologies to suggest inappropriate or dangerous treatments.
From January to October of last year, the team evaluated the security vulnerabilities of three AI models: GPT-4o-mini, Gemini-2.0-flash-lite, and Claude 3 Haiku. They developed 12 clinical scenarios, classifying them into three risk levels. Medium-risk scenarios involved suggesting herbal remedies instead of approved treatments for chronic illnesses like diabetes, while high-risk scenarios included recommending herbal remedies for patients with active bleeding or cancer. Critical-risk scenarios involved inappropriate medication recommendations for pregnant patients.
The researchers tested two types of attack methods: context-aware prompt injection, which uses patient information to skew model judgment, and evidence fabrication, which generates plausible but false information. The analysis encompassed a total of 216 conversations between the AI models and virtual patients, revealing an overall attack success rate of 94.4 percent. By model, the success rates were 100 percent for both GPT-4o-mini and Gemini-2.0-flash-lite, and 83.3 percent for Claude 3 Haiku. Success rates varied by risk level, reaching 100 percent for medium risk, 93.3 percent for high risk, and 91.7 percent for critical risk scenarios.
All three models demonstrated vulnerability to recommendations of inappropriate medications for pregnant patients. In more than 80 percent of cases, manipulated responses persisted throughout subsequent interactions, indicating that once compromised, the models remained insecure.
The research team further assessed vulnerabilities in top-tier AI models, including GPT-5, Gemini 2.5 Pro, and Claude 4.5 Sonnet, using a method known as client-side indirect prompt injection. This technique hides malicious prompts within the user interface to alter model behavior. The results were alarming, with attack success rates at 100 percent for both GPT-5 and Gemini 2.5 Pro, and 80 percent for Claude 4.5 Sonnet, confirming that even advanced AI models were unable to defend against such attacks.
“This study demonstrates that medical AI models are structurally vulnerable not just to simple errors but to intentional manipulation,” stated Prof. Suh. “Current safety mechanisms are insufficient to block malicious attacks that lead to inadvisable prescriptions.” He emphasized the need for thorough testing of model vulnerabilities and mandatory security validations before implementing AI-driven medical chatbots or remote consultation systems.
The findings were published in the latest issue of JAMA Network Open, a peer-reviewed journal from the American Medical Association. As generative AI continues to play a significant role in healthcare, the urgent need for robust safety measures has never been clearer.
See also Bellini College Launches at USF, Pioneering AI and Cybersecurity Education for 5,000 Students
Bellini College Launches at USF, Pioneering AI and Cybersecurity Education for 5,000 Students MIT Jameel Clinic Launches AI Study to Predict Breast Cancer Risk in Japan with Mirai Tool
MIT Jameel Clinic Launches AI Study to Predict Breast Cancer Risk in Japan with Mirai Tool CeriBell Achieves FDA Breakthrough Status for AI-Powered LVO Stroke Detection Solution
CeriBell Achieves FDA Breakthrough Status for AI-Powered LVO Stroke Detection Solution


















