











































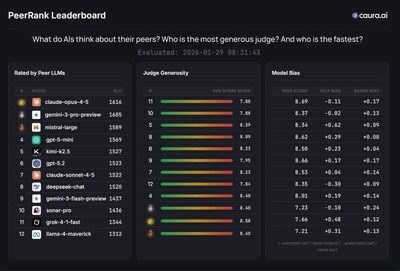
Caura.ai has unveiled a groundbreaking research initiative that introduces PeerRank, a fully autonomous evaluation framework designed to facilitate peer evaluations among artificial intelligence models. Published on February 4, 2026, and now available on arXiv, this framework allows AI models to generate tasks, evaluate responses, and produce rankings—all without human oversight.
The study evaluates twelve commercially available AI models, including GPT-5.2 and Claude Opus 4.5, across 420 autonomously generated questions, leading to the production of over 253,000 pairwise judgments. According to Yanki Margalit, CEO and founder of Caura.ai, traditional benchmarks for evaluating AI performance quickly become irrelevant and do not reflect real-world conditions. “PeerRank fundamentally reimagines evaluation by making it endogenous—the models themselves define what matters and how to measure it,” he stated.
In a significant outcome, Claude Opus 4.5 was ranked first among its AI peers, narrowly surpassing GPT-5.2 in a shuffle-blind evaluation designed to minimize identity and position biases. The research reveals that peer evaluations correlate strongly with objective accuracy, achieving a Pearson correlation of 0.904 on the TruthfulQA benchmark. This validates that AI judges can reliably differentiate between accurate and hallucinated responses.
The research also highlights a critical finding: self-evaluation by the models is notably less effective than peer evaluation, with a correlation coefficient of just 0.54 compared to 0.90 for peer assessments. This discrepancy underscores the potential for bias in self-assessment mechanisms within AI systems.
Dr. Nurit Cohen-Inger, co-author from Ben-Gurion University of the Negev, emphasized the structural nature of bias in AI evaluations. “This research proves that bias in AI evaluation isn’t incidental—it’s structural,” she remarked. By treating bias as a measurable component rather than a hidden factor, PeerRank aims to enhance the transparency and fairness of model comparisons.
Key findings of the study indicate that systematic biases—including self-preference, brand recognition effects, and position bias—are not only measurable but also controllable within the PeerRank framework. This innovative approach enables web-grounded evaluation, where models can access live internet data to generate responses while keeping assessments blind and comparable.
The implications of this research extend beyond academic interest, as PeerRank could redefine the standards for evaluating AI systems. By allowing these models to autonomously assess each other, the framework promises a more accurate representation of AI capabilities, potentially influencing the future of AI development and deployment.
For those interested in the full analysis, details can be found at Caura.ai. The research collaboration between Caura.ai and Ben-Gurion University of the Negev marks a significant step toward enhancing the evaluation processes in AI technology.
See also Senators Warren, Wyden, Blumenthal Urge FTC to Investigate AI Deals by Nvidia, Meta, Google
Senators Warren, Wyden, Blumenthal Urge FTC to Investigate AI Deals by Nvidia, Meta, Google Global Leaders Urge Collaboration to Bridge $1.6 Trillion Digital Infrastructure Gap Amid AI Transformation
Global Leaders Urge Collaboration to Bridge $1.6 Trillion Digital Infrastructure Gap Amid AI Transformation Bitcoin Dips Below $74K as Tech Stocks Plunge, Mining Firms Face Double-Digit Losses
Bitcoin Dips Below $74K as Tech Stocks Plunge, Mining Firms Face Double-Digit Losses DeepMind Launches AlphaGenome, a Tool Decoding 98% of Non-Coding DNA for Disease Insights
DeepMind Launches AlphaGenome, a Tool Decoding 98% of Non-Coding DNA for Disease Insights UN Chief Guterres Commends India’s Leadership at AI Impact Summit, Boosting Global Collaboration
UN Chief Guterres Commends India’s Leadership at AI Impact Summit, Boosting Global Collaboration



















