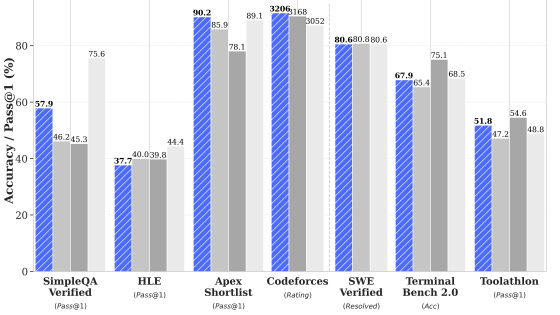
The artificial intelligence industry is experiencing a pivotal shift, termed the “DeepSeek Effect,” following the release of DeepSeek-V3 and DeepSeek-R1 in early 2025. This transformation has fundamentally disrupted the “brute force” scaling approach, which characterized AI development in the previous half-decade. By demonstrating that frontier-level intelligence could be achieved at significantly reduced training costs—specifically, approximately $6 million for a GPT-4 class model—DeepSeek has compelled leading semiconductor firms to prioritize architectural efficiency over sheer computational power.
As of early 2026, the implications of this shift are reverberating through stock markets and data center construction. The focus has shifted away from constructing the largest GPU clusters toward a “sparse computation” model. This new paradigm emphasizes silicon capable of directing data efficiently, ending the era of dense models that demanded maximum transistor activation for every operation. Such developments necessitate a comprehensive redesign of the AI stack, impacting everything from transistor gate levels to the sprawling interconnect systems of global data centers.
Market Context
Central to the DeepSeek Effect are three technical innovations: Mixture-of-Experts (MoE), Multi-Head Latent Attention (MLA), and Multi-Token Prediction (MTP). While MoE has been in existence, the recent iteration in DeepSeek-V3 has scaled it to an unprecedented 671 billion parameters, with only 37 billion parameters activated for any given token. This design allows models to harness vast amounts of knowledge while minimizing computational needs. Consequently, chipmakers are now prioritizing routing efficiency—how quickly a chip can activate the appropriate “expert” circuit for specific inputs—over traditional matrix-multiplication speeds.
The most significant breakthrough is MLA, which addresses the “KV Cache bottleneck” that has plagued prior models. By compressing key-value cache into a low-dimensional latent space, MLA reduces memory overhead by up to 93%, enabling lower-capacity chips to manage extensive context windows once reserved for top-tier accelerators costing upwards of $40,000. The AI research community reacted with both shock and a need for strategic recalibration, as DeepSeek’s accomplishments highlighted that algorithmic innovation could replace the need for massive silicon investments.
The market reaction was swift, particularly following “DeepSeek Monday” in late January 2025, when NVIDIA (NASDAQ: NVDA) suffered a staggering $600 billion loss in market value as investors reevaluated the long-term viability of large H100 clusters. In response, NVIDIA has pivoted its roadmap, expediting the release of its Rubin architecture, engineered specifically for sparse MoE models. This new architecture includes dedicated “MoE Routers” to reduce expert-switching latency, positioning NVIDIA as an “efficiency-first” company.
Custom silicon designers have emerged as the primary beneficiaries of the DeepSeek Effect. Companies like Broadcom (NASDAQ: AVGO) and Marvell (NASDAQ: MRVL) are seeing increased orders as AI labs transition from general-purpose GPUs to Application-Specific Integrated Circuits (ASICs). In a noteworthy $21 billion deal disclosed this month, Anthropic has commissioned nearly one million custom “Ironwood” TPU v7p chips from Broadcom, designed to optimize inference costs for its new Claude architectures. Marvell, too, is advancing its offerings, incorporating “Photonic Fabric” into its 2026 ASICs to manage the high-speed data routing essential for decentralized MoE experts.
Traditional chipmakers, including Intel (NASDAQ: INTC) and AMD (NASDAQ: AMD), have also adapted to this new focus on efficiency. Intel’s upcoming “Crescent Island” GPU, launching later this year, avoids the costly HBM memory competition by utilizing 160GB of high-capacity LPDDR5X. This move aligns with the DeepSeek Effect, as MoE models are more memory-bound than compute-bound, emphasizing the need for larger, cost-effective memory pools. Similarly, AMD’s Instinct MI400 is geared toward accommodating the extensive parameter counts of sparse models with its substantial 432GB HBM4 configurations.
The broader implications of the DeepSeek Effect extend into global energy and geopolitical arenas. By demonstrating that high-tier AI can operate without the need for exorbitantly expensive data centers, DeepSeek has enabled smaller nations and companies to vie for a place in the AI landscape. This has sparked a “Sovereign AI” movement, prompting countries to invest in smaller, highly efficient domestic clusters instead of relying on centralized American hyperscalers. The focus has shifted from “How many GPUs can we buy?” to “How much intelligence can we generate per watt?”
Environmentally, the transition to sparse computation represents a significant advancement in AI. Dense models are notorious for their high power consumption, as they activate all transistors during operations. In contrast, DeepSeek-style models activate only about 5-10% of their parameters for any given token, theoretically offering a tenfold increase in energy efficiency for inference. As global power grids struggle to meet rising AI demands, the DeepSeek Effect serves as a critical mechanism for scaling intelligence without a corresponding rise in carbon emissions.
However, this shift raises questions about the potential “commoditization of intelligence.” As training costs decline, the competitive advantage for leading firms like OpenAI (NASDAQ: MSFT) and Google (NASDAQ: GOOGL) may evolve from “owning the best model” to “having the best data” or “the best user integration.” This has prompted a flurry of acquisitions in early 2026 as AI labs seek vertical integration with hardware providers to secure optimized “silicon-to-software” stacks.
Looking ahead, the industry anticipates the arrival of “DeepSeek-V4” and its competitors, introducing “dynamic sparsity.” This technology would allow models to adjust their active parameter counts according to task complexity, necessitating a new generation of hardware with enhanced flexibility. In the near future, the DeepSeek Effect is expected to transition from data centers to edge computing, with specialized Neural Processing Units (NPUs) in consumer devices like smartphones and laptops designed to natively handle sparse weights. By 2027, “Reasoning-as-a-Service” may be conducted locally on these devices, significantly reducing reliance on cloud APIs for everyday AI tasks.
The ultimate ambition within the field is the “One Watt Frontier Model”—an AI capable of human-level reasoning that operates within the power budget of a lightbulb. While the industry is still working toward this goal, the DeepSeek Effect has clearly illustrated that the pathway to Artificial General Intelligence (AGI) is not solely through increased power and silicon but rather through smarter, more efficient utilization of existing resources.
See also AI’s Employment Impact: Key Insights on Worker Displacement and Adaptation Strategies
AI’s Employment Impact: Key Insights on Worker Displacement and Adaptation Strategies Google Launches Gemini’s Personal Intelligence, Enhancing AI with User Data Integration
Google Launches Gemini’s Personal Intelligence, Enhancing AI with User Data Integration Notre Dame Secures $50.8M Grant to Shape Christian Ethics for AI Development
Notre Dame Secures $50.8M Grant to Shape Christian Ethics for AI Development GPT-5.2 Achieves Milestone by Solving Long-Standing Erdős Problems, Transforming AI in Mathematics
GPT-5.2 Achieves Milestone by Solving Long-Standing Erdős Problems, Transforming AI in Mathematics