
































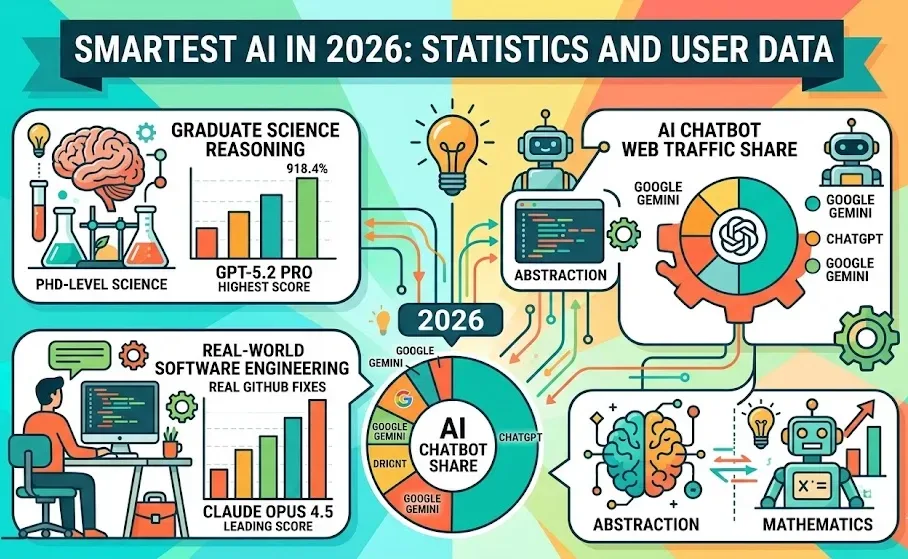
In a competitive landscape of artificial intelligence, no single model dominates every benchmark as of January 2026. The latest iterations of leading AI models reveal varying strengths across different performance metrics. The GPT-5.2 Pro scores 93.2% on the GPQA Diamond test, demonstrating the highest proficiency in graduate-level reasoning, while Claude Opus 4.5 excels in real-world software engineering with an 80.9% score in SWE-bench Verified. Meanwhile, Gemini 3 Pro leads in abstract generalization, outperforming its peers in that specific domain.
The benchmark scores highlight significant advancements among AI models, yet they also underscore the tailored strengths of each system. The GPQA Diamond assessment, focused on PhD-level biology, physics, and chemistry, has seen several models surpass human expert performance, complicating direct comparisons. The SWE-bench Verified test, which evaluates real GitHub bug fixes, has become an essential metric for software engineering applications, reflecting the practical capabilities of these AI systems.
The performance statistics are striking. GPT-5.2 Pro leads on GPQA Diamond, followed closely by Gemini 3 Pro at 91.9%, while Claude Opus 4.5 maintains a solid performance at 87.0%. On the SWE-bench Verified metric, Claude Opus 4.5 outpaces Gemini 3 Pro at 80.9% compared to 78.8%. Surprisingly, GPT-5.2 Pro lags behind in this area, scoring only 55.6%, illustrating that no single benchmark can comprehensively capture an AI model’s overall capability.
Shifts in the AI chatbot market reflect a dynamic competitive atmosphere. As of January 2026, ChatGPT commands 68% of AI chatbot web traffic, a significant decrease from 87.2% one year prior. In contrast, Google Gemini has made substantial gains, rising from 5.4% to 18.2% in the same timeframe, marking the most considerable market share shift in generative AI. Claude, with a modest web traffic share of under 3%, generated an estimated $850 million in annual revenue for 2024, with projections indicating a rise to $2.2 billion in 2025, primarily from enterprise clients.
Specific tasks reveal which models excel under different conditions. For graduate science reasoning, GPT-5.2 Pro leads with a score of 93.2%, while Gemini 3 Pro follows closely at 91.9%. In competition mathematics, Gemini 3 Pro in Deep Think mode achieved a score of 95% on the AIME 2025, surpassing Grok 3’s 93.3%. For abstract generalization, Gemini 3 Pro scores 45.1% on ARC-AGI-2, with Claude Opus 4.5 at 37.6%, both significantly ahead of GPT-5.1, which scored only 17.6%.
Cost efficiency also plays a crucial role in model selection. DeepSeek R1 equaled Claude 3.5 Sonnet on the MATH-500 benchmark with a 97.3% score, while its cost per output token is approximately 94% less than that of Claude Opus 4.5. This cost differential is pivotal for organizations processing high volumes of math or scientific tasks, potentially shifting their deployment strategies.
Despite the advancements in benchmark testing, significant limitations remain. Many assessments, including MATH-500, may contain test contamination, as models often encounter similar problems during training, inflating scores. While SWE-bench and ARC-AGI-2 strive for greater reliability through out-of-distribution design, no benchmark is entirely immune to these issues. Furthermore, latency concerns, particularly in extended-reasoning modes, can impact the suitability of models for applications demanding rapid response times.
As AI technology progresses, organizations looking to select the best model for their specific needs should consider running tests on their representative data rather than relying solely on published leaderboards. This approach offers a more tailored assessment of an AI model’s capabilities, ensuring that the chosen system aligns effectively with operational requirements.
See also Sam Altman Praises ChatGPT for Improved Em Dash Handling
Sam Altman Praises ChatGPT for Improved Em Dash Handling AI Country Song Fails to Top Billboard Chart Amid Viral Buzz
AI Country Song Fails to Top Billboard Chart Amid Viral Buzz GPT-5.1 and Claude 4.5 Sonnet Personality Showdown: A Comprehensive Test
GPT-5.1 and Claude 4.5 Sonnet Personality Showdown: A Comprehensive Test Rethink Your Presentations with OnlyOffice: A Free PowerPoint Alternative
Rethink Your Presentations with OnlyOffice: A Free PowerPoint Alternative OpenAI Enhances ChatGPT with Em-Dash Personalization Feature
OpenAI Enhances ChatGPT with Em-Dash Personalization Feature