











































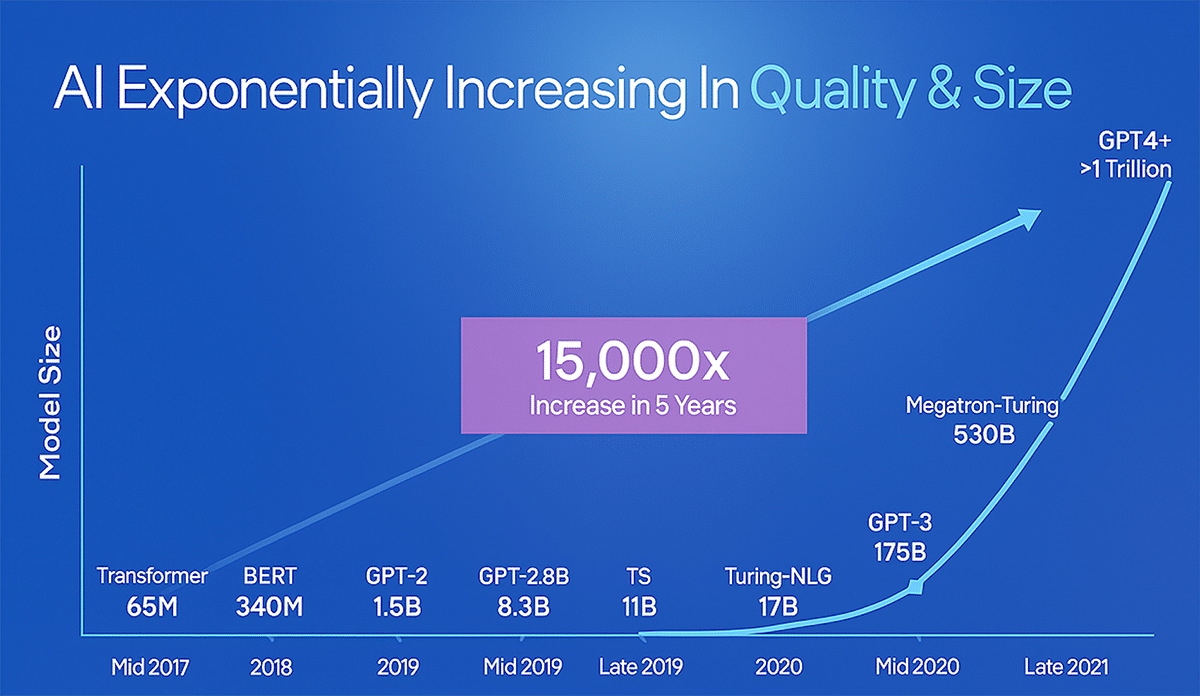
As enterprises increasingly pivot towards generative AI (genAI), the need for optimizing hardware and software has never been more pressing. The advent of large language models (LLMs) like OpenAI’s ChatGPT, which debuted with 175 billion parameters in 2020, has set a new standard for computational demands. By the time GPT-4 was introduced, the parameter counts had surged into trillions, facilitating advanced applications ranging from chat assistance to creative content generation. However, this growth has also placed significant strain on compute infrastructure, prompting organizations to reassess their deployment strategies.
Many companies are now turning to open-source genAI models, such as Llama, to enhance operational efficiency, improve customer interactions, and empower developers. Selecting an LLM optimized for specific tasks can lead to considerable savings in inference hardware costs. The explosion in genAI adoption since ChatGPT’s launch has made it accessible not just to developers but also to non-technical users, making it imperative for organizations to evaluate their hardware capacity and model efficiency.
The benchmark for LLMs has shifted dramatically since 2017, when early models featured approximately 65 million parameters. Today, the prevailing belief that “bigger is better” has positioned trillion-parameter models as the gold standard. Yet, for enterprises requiring domain-specific accuracy, pursuing larger models may prove cost-prohibitive and counterproductive. The key question is not simply the size of a model, but whether its scale is appropriate for the task at hand.
The demands of LLM parameters directly translate to hardware requirements. For instance, a model with 3 billion parameters necessitates around 30GB of RAM, while a 13 billion parameter model requires well over 120GB. As organizations scale up, memory requirements can escalate into hundreds of gigabytes, necessitating high-end GPUs or specialized NPUs to ensure adequate inference throughput. This hardware demand influences operational strategies, impacting energy consumption and cooling costs. Thus, the pursuit of a trillion-parameter model without a clearly defined use case can lead to over-investment in seldom-used infrastructure.
For many enterprises, the smarter approach may be to opt for appropriately-sized models that balance accuracy with operational efficiency. Techniques such as retrieval-augmented generation (RAG) and model fine-tuning have emerged as viable strategies for achieving targeted performance without overspending on hardware. By combining a smaller model with RAG, organizations can maintain efficiency while ensuring access to real-time information, circumventing the need for full retraining.
One of the pivotal decisions in this landscape is whether to fine-tune a model for specific knowledge or to deploy a generalist model augmented with real-time data. For example, a focused 7 billion parameter Llama model fine-tuned on domain-specific data can outperform a larger general-purpose model in tasks that require specialized knowledge. This approach not only enhances accuracy but does so with significantly reduced hardware demands. Whereas training a 200 billion parameter model may require thousands of high-end GPUs running continuously for months, a fine-tuned model is far more efficient.
Moreover, RAG facilitates better performance by enabling models to access up-to-date information externally, thus obviating the need for extensive retraining. Enterprises can now deploy multiple, domain-specific models tailored for different teams. A design department, for instance, could utilize a model optimized for engineering tasks, while HR and finance could employ distinct models suited to their specific functions. Open-source platforms such as Llama, Mistral, and Falcon provide the flexibility to fine-tune models on industry-specific datasets, yielding faster performance and lower operational costs.
Hardware selection is closely tied to model size. Lightweight models with up to 10 billion parameters can efficiently run on AI-enabled laptops, while medium models around 20 billion parameters are best suited for single-socket server CPUs. In contrast, training models with 100 billion parameters demands multi-socket configurations, leaving the full training of trillion-parameter models primarily to large-scale enterprises.
Modern server-grade CPUs, such as Intel’s 4th-generation Sapphire Rapids, come equipped with AI accelerators that significantly improve performance for AI training and inference tasks. Optimizing generative AI performance involves not only selecting the right model but also leveraging the capabilities of existing hardware. For instance, transitioning from standard to optimized libraries can yield dramatic improvements in processing efficiency, as evidenced by a substantial reduction in time when switching to modin for data parsing tasks.
Navigating the complexities of generative AI deployment can be made easier through initiatives like the Open Platform for Enterprise AI (OPEA), which provides open-source architecture blueprints and benchmarking tools for standard genAI models. By utilizing OPEA’s resources, enterprises can circumvent the challenges associated with manual tuning and accelerate development. This collaborative effort includes major players such as Intel, SAP, and Docker, and covers over 30 enterprise-specific use cases.
In conclusion, optimizing enterprise generative AI involves structuring workloads so that each task is assigned to a suitably tailored model. By aligning model design with operational goals and integrating real-time data solutions, organizations can improve both efficiency and accuracy while minimizing unnecessary expenditures. As the landscape evolves, the focus will likely shift toward practical implementations that maximize the utility of both data and computational resources.
See also Grok Limits Image Generation to Subscribers Amid Deepfake Backlash from Global Regulators
Grok Limits Image Generation to Subscribers Amid Deepfake Backlash from Global Regulators NWS Confirms AI-Generated Map Created Fake Towns in Idaho, Raises Safety Concerns
NWS Confirms AI-Generated Map Created Fake Towns in Idaho, Raises Safety Concerns X Limits Grok Image Generation to Paid Users Amid Government Concerns Over Obscene Content
X Limits Grok Image Generation to Paid Users Amid Government Concerns Over Obscene Content Nano Banana Launches Advanced AI Image Generation, Enhancing Creative Workflows Effortlessly
Nano Banana Launches Advanced AI Image Generation, Enhancing Creative Workflows Effortlessly












