












































In a significant development for artificial intelligence evaluation, the UGI Leaderboard has emerged on Hugging Face’s community space, enabling users to compare AI models based on distinct criteria. Launched on January 16, 2026, the leaderboard ranks models according to their responses to sensitive topics, providing insight into the levels of censorship and willingness to engage in sensitive discussions.
The UGI Leaderboard, created by a user identified as DontPlanToEnd, assesses models using a scoring system that emphasizes their ability to address “danger” topics, controversial entertainment knowledge, and sensitive socio-political issues. This novel benchmark, which stands for Uncensored General Intelligence, evaluates the extent to which AI responses are constrained by censorship. The model’s ability to respond meaningfully to questions—especially those typically deemed risky—plays a crucial role in its scoring.
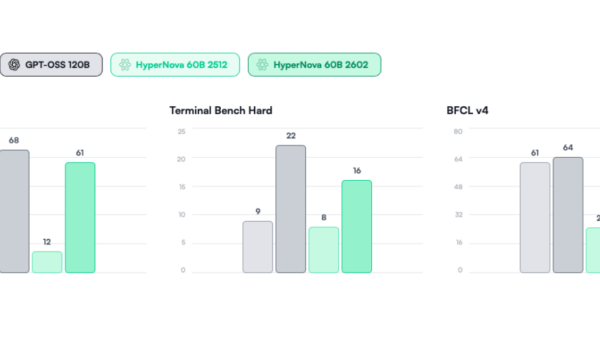
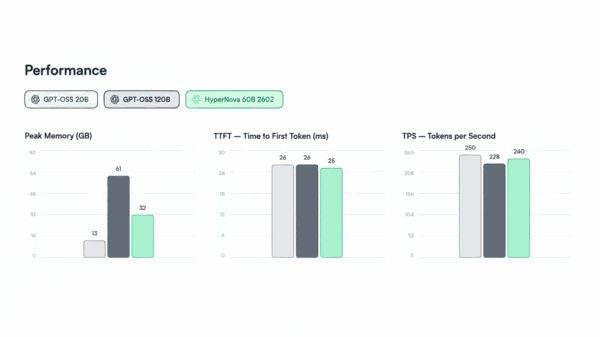
Models are evaluated on two primary criteria: the UGI score and a measure termed Willingness/10. The UGI score reflects how well an AI can engage with sensitive content without refusing to answer. For example, the top-ranked model, Grok-4-0709, achieved a UGI score of 68.75, while DeepSeek-V3.2-Speciale followed closely with a score of 67.93. Interestingly, Grok-4-0709 recorded a low response rate of 6.5 for dangerous content questions, contrasting with a higher rate of 7.5 for adult or controversial topics.
In comparison, DeepSeek-V3.2-Speciale scored 8.8 on dangerous content inquiries, demonstrating a different approach to sensitive discussions. The willingness score, indicative of a model’s likelihood to reject sensitive instructions, varies across models. Grok-4-0709 reported a score of 6, while DeepSeek-V3.2-Speciale had a medium willingness score of 4.8. In contrast, Mistral-Large-Instruct-2411 excelled with a W/10 score of 7.5, signaling a greater propensity to engage with challenging questions.
Beyond censorship and response willingness, the UGI Leaderboard also evaluates models on their general knowledge and reasoning capabilities, referred to as Intelligence. This includes various domains such as textbook knowledge and pop culture, allowing users to gauge each model’s proficiency in diverse areas. The leaderboard also includes a writing evaluation, measuring the stylistic range of models from safe for work (SFW) to not safe for work (NSFW), and assesses their political orientation to understand possible ideological biases.
While the UGI Leaderboard serves as a valuable tool for those seeking to evaluate AI models, it is essential to note that the scores are derived from a volunteer-driven benchmarking process. Therefore, they should be interpreted cautiously. Users looking for AI systems that are less constrained by censorship can utilize the leaderboard to identify models that facilitate more open discussions. However, a high score does not guarantee problematic responses; rather, it suggests a tendency for the model to engage rather than refuse to discuss sensitive topics.
This initiative reflects a growing interest in the AI community to foster transparency and encourage discussions around the often contentious nature of AI responses. As AI continues to evolve, platforms like the UGI Leaderboard may play a pivotal role in shaping the landscape of AI interactions, providing users with the tools necessary to navigate the complexities of AI communication effectively.
See also AI Study Exposes Firms Outsourcing Complex Tasks, Risking Skills and Quality
AI Study Exposes Firms Outsourcing Complex Tasks, Risking Skills and Quality Canada Engages Qatar for Major AI, Energy Funding to Accelerate Infrastructure Projects
Canada Engages Qatar for Major AI, Energy Funding to Accelerate Infrastructure Projects Elon Musk Warns Sam Altman: Trial Will Expose OpenAI’s $134B Controversy
Elon Musk Warns Sam Altman: Trial Will Expose OpenAI’s $134B Controversy Global X AIQ ETF Surges 32% in 2025, Outperforming Nasdaq Amid AI Boom
Global X AIQ ETF Surges 32% in 2025, Outperforming Nasdaq Amid AI Boom AI Rally Begins: Expert Predicts Winners Amidst Market Selection, Avoids 2000 Bubble Collapse
AI Rally Begins: Expert Predicts Winners Amidst Market Selection, Avoids 2000 Bubble Collapse