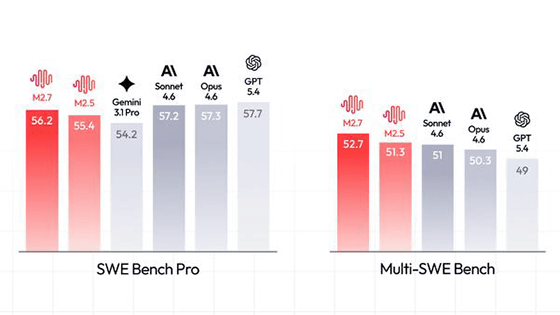
In a recent tutorial, developers showcased a comprehensive workflow for high-quality image generation using the Diffusers library, emphasizing practical techniques that blend speed, quality, and control. This workflow enables the creation of detailed images from text prompts utilizing the Stable Diffusion model, augmented by an optimized scheduler and advanced editing capabilities.
The process begins with establishing a stable environment, setting up dependencies, and preparing necessary libraries. The tutorial emphasizes the importance of resolving any potential conflicts, particularly with the Pillow library, to ensure reliable image processing. By leveraging the Diffusers ecosystem, developers import core modules essential for generating images, controlling outputs, and performing inpainting tasks.
Key utility functions are defined to facilitate reproducibility and organize visual outputs. Developers establish global random seeds to maintain consistency in generation across different runs. Additionally, the runtime environment is configured to utilize either GPU or CPU, optimizing performance based on available hardware.
After setting the groundwork, the tutorial introduces the Stable Diffusion pipeline, initializing it with a base model and implementing the efficient UniPC scheduler. A high-quality image is then generated from a descriptive text prompt, effectively balancing guidance and resolution to create a strong foundation for further enhancements.
A notable enhancement involves the integration of a LoRA (Low-Rank Adaptation) approach, which accelerates inference. Through this method, developers demonstrate the ability to produce quality images rapidly using significantly fewer diffusion steps. The tutorial showcases how to construct a conditioning image that guides composition, further enhancing creative control in the generation process.
To refine the generated images, the tutorial employs ControlNet, allowing for structured guidance in layout design. In a step showcasing this capability, a structural conditioning image is created, and the generated scene is adapted to respect the specified composition while still leveraging imaginative text prompts. This combination of structure and creativity demonstrates the potential for sophisticated image generation workflows.
In the final stages of image processing, developers utilize inpainting techniques to target specific areas within the generated images. This technique allows for localized modifications, enhancing certain elements without disturbing the overall composition. A glowing neon sign is added to an otherwise complete scene, showcasing the flexibility of the Diffusers library in real-world applications.
All outputs are saved systematically, ensuring that both intermediate and final results are preserved for further inspection and reuse. As a result, the tutorial not only illustrates the capabilities of the Diffusers library but also provides a roadmap for building a flexible and production-ready image generation system.
This systematic approach offers insights into moving from standard text-to-image generation to incorporating advanced techniques such as fast sampling, structural control, and targeted editing. By combining elements like schedulers, LoRA adapters, ControlNet, and inpainting, developers can create highly controllable and efficient generative pipelines. This tutorial serves as a critical resource for those looking to harness the power of AI-driven image generation in creative or applied contexts.
See also Dow Jones Futures Surge After Supreme Court Tariff Ruling; Nvidia’s AI Growth Drives Market
Dow Jones Futures Surge After Supreme Court Tariff Ruling; Nvidia’s AI Growth Drives Market Mistral AI’s Arthur Mensch Advocates for Decentralized AI Power at India Summit
Mistral AI’s Arthur Mensch Advocates for Decentralized AI Power at India Summit Demis Hassabis Claims AGI Will Exceed Industrial Revolution’s Impact in Just 10 Years
Demis Hassabis Claims AGI Will Exceed Industrial Revolution’s Impact in Just 10 Years Cohere Launches Tiny Aya, Achieving $240M ARR and Paving the Way for 2026 IPO
Cohere Launches Tiny Aya, Achieving $240M ARR and Paving the Way for 2026 IPO Joyland AI Traffic Declines 35% to 3.49 Million Monthly Visits by December 2025
Joyland AI Traffic Declines 35% to 3.49 Million Monthly Visits by December 2025