































Researchers at Google have introduced a novel training method aimed at enhancing the capabilities of large language models (LLMs) to approximate Bayesian reasoning. This approach focuses on how these models can effectively update their beliefs when faced with new information during multi-step user interactions, a crucial aspect in applications such as recommendation systems.
The study investigates how language models adapt their beliefs over time while interacting with users. In real-world scenarios, models are often required to deduce user preferences gradually as new data emerges. Utilizing Bayesian inference—a mathematical framework for probability updates—the researchers sought to determine if language models could align their behaviors with Bayesian belief updates and to explore training methods to enhance this ability.
To assess these capabilities, the team designed a simulated flight recommendation task. In this experiment, a model engaged with a simulated user across five interaction rounds. During each round, the assistant and user were presented with three flight options characterized by attributes like departure time, duration, number of stops, and price. Each simulated user held hidden preferences regarding these attributes. Following each recommendation, the user indicated whether the assistant had chosen the correct option and disclosed their preferred flight. The assistant was expected to leverage this feedback to refine future recommendations.
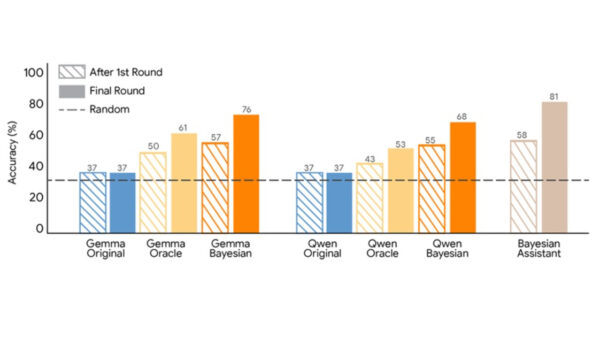
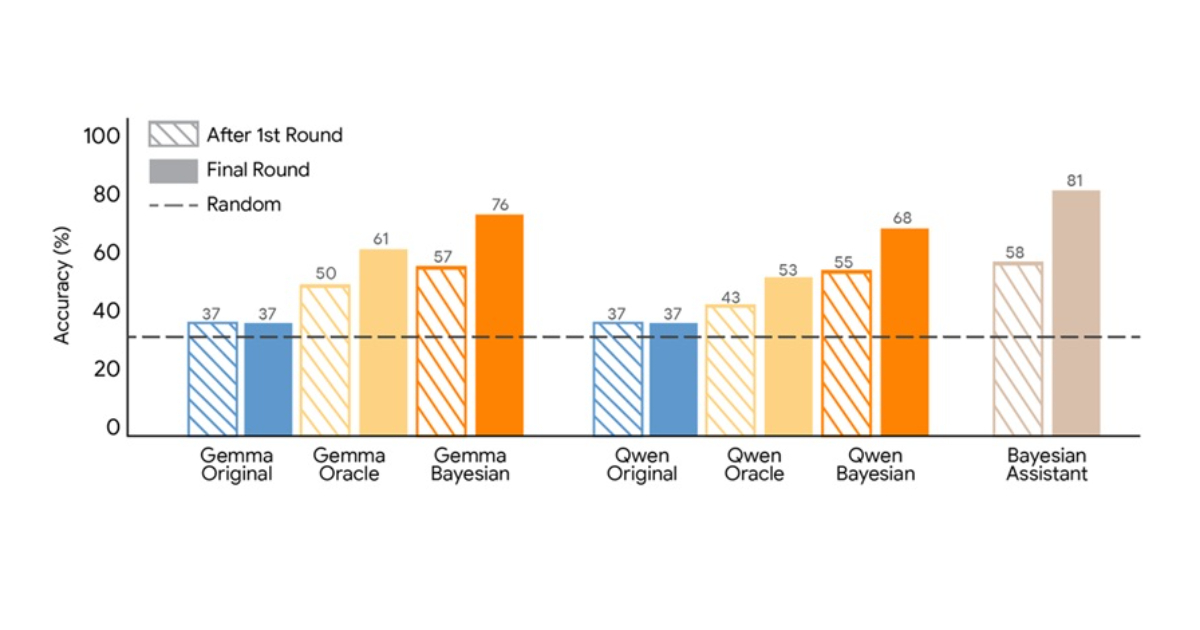
In comparing various language models to a Bayesian assistant—which maintains a probability distribution over potential user preferences and updates it based on Bayes’ rule after each interaction—the results revealed a stark divergence in performance. The Bayesian assistant achieved approximately 81% accuracy in selecting the correct flight option, while the language models lagged behind, exhibiting limited improvement after the initial interaction. This indicated that the LLMs struggled to effectively recalibrate their internal estimates of user preferences.
Subsequently, the researchers explored a training method dubbed Bayesian teaching. Rather than solely learning from correct answers, this method trained models to mimic the predictions made by the Bayesian assistant throughout their simulated interactions. In earlier rounds, though the Bayesian assistant occasionally made incorrect recommendations due to uncertainty about user preferences, its decisions nonetheless reflected a probabilistic reasoning framework based on available evidence.
The training data for supervised fine-tuning was derived from simulated conversations between users and the Bayesian assistant. To establish a benchmark, the researchers also evaluated a method where the model learned from an assistant that always opted for the correct choice, equipped with perfect knowledge of user preferences. Both fine-tuning approaches enhanced model performance, but Bayesian teaching yielded superior results. Models trained through this method produced predictions that more closely mirrored those of the Bayesian assistant and showed greater improvement across multiple interaction rounds. Additionally, the trained models displayed a higher agreement with the Bayesian system when assessing user choices.
The Google Research post drew a largely positive reception from the community, with many commentators noting the advancements in probabilistic reasoning and multi-turn adaptation exhibited by LLMs. Software developer Yann Kronberg remarked on the significance of the research, stating, “People talk about reasoning benchmarks but this is basically about belief updates. We know that most LLMs don’t revise their internal assumptions well after new information arrives, so @GoogleResearch teaching them to approximate Bayesian inference could matter a lot for long-running agents.”
However, some critiques emerged regarding the choice of supervised fine-tuning instead of reinforcement learning (RL) for approximating Bayesian inference. Researcher Aidan Li questioned, “Why did the authors use SFT instead of RL to train the model to approximate probabilistic inference? There is a wealth of work relating RL and probabilistic inference, even for LLMs. Maybe I’m missing something but RL seems like the obvious choice.”
The Google researchers position their method as a form of model distillation, wherein a neural network learns to emulate the behavior of a symbolic system that implements Bayesian inference. The findings suggest that language models can acquire probabilistic reasoning skills through post-training, demonstrating optimal decision strategies during sequential interactions. As AI continues to evolve, establishing a stronger foundation for probabilistic reasoning in LLMs could significantly enhance their functionality in various complex applications.
See also Sam Altman Praises ChatGPT for Improved Em Dash Handling
Sam Altman Praises ChatGPT for Improved Em Dash Handling AI Country Song Fails to Top Billboard Chart Amid Viral Buzz
AI Country Song Fails to Top Billboard Chart Amid Viral Buzz GPT-5.1 and Claude 4.5 Sonnet Personality Showdown: A Comprehensive Test
GPT-5.1 and Claude 4.5 Sonnet Personality Showdown: A Comprehensive Test Rethink Your Presentations with OnlyOffice: A Free PowerPoint Alternative
Rethink Your Presentations with OnlyOffice: A Free PowerPoint Alternative OpenAI Enhances ChatGPT with Em-Dash Personalization Feature
OpenAI Enhances ChatGPT with Em-Dash Personalization Feature