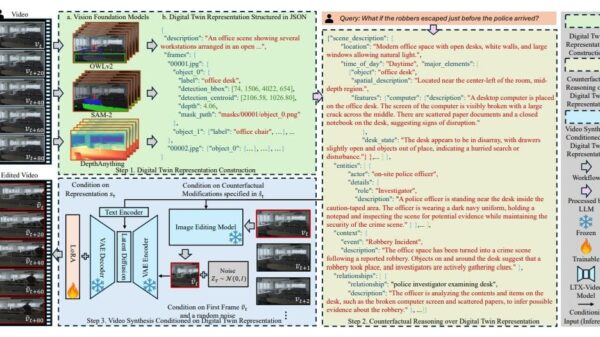







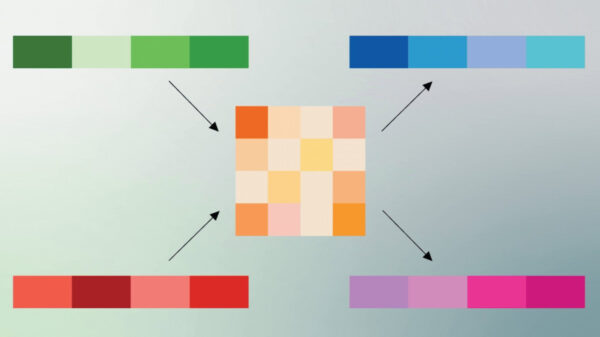

































In a notable advancement for generative modeling, researchers at Johns Hopkins University, led by Amandeep Kumar and Vishal M. Patel, have unveiled a new method to tackle the inefficiencies of standard diffusion transformers in high-fidelity image generation. Their study highlights a significant geometric issue, termed Geometric Interference, which hampers the ability of these models to learn effectively from representation encoders. Published recently, the research proposes a novel technique called Riemannian Flow Matching with Jacobi Regularization (RJF), which optimizes the generative process by adhering to the natural geometry of representation manifolds.
Standard diffusion models often struggle with poor learning outcomes due to what the researchers describe as inefficient probability paths that traverse low-density regions of the feature space. This structural mismatch arises when diffusion transformers, assumed to operate in Euclidean space, interact with the inherently hyperspherical nature of representation encoders like DINOv2. The research indicated that the inefficiencies stem from linear paths cutting through areas where the representation space is undefined, rather than following the natural geodesics of the manifold.
The introduction of RJF aims to rectify these issues. By employing Spherical Linear Interpolation, this method constrains generative processes to remain on the manifold surface, effectively circumventing the low-density interiors that hinder learning. Additionally, the incorporation of a Jacobi Regularization term adjusts for curvature-induced distortions in the generative paths, enhancing overall accuracy. Early experiments demonstrate the method’s promise, achieving a Fréchet Inception Distance (FID) of 3.37, a notable improvement over previous techniques.
Further experimentation using the LightingDiT-B architecture yielded an FID of 4.95 without guidance, significantly outperforming the base VAE-based LightingDiT-B model, which recorded an FID of 15.83. This success illustrates RJF’s capacity for effective convergence without requiring computationally expensive architectural modifications, such as width scaling. The study emphasizes that the failure of standard models to converge under similar conditions was misattributed to inadequate model capacity rather than the critical influence of geometric considerations.
The DiT-B architecture, featuring 131 million parameters, was initially tested with standard diffusion methods but showed convergence issues when applied to high-dimensional latent spaces. The team identified Geometric Interference as the central obstacle, revealing that conventional approaches forced paths through low-density regions instead of along the manifold surface. RJF’s design ensures the generative model learns effective paths, thus enhancing both the fidelity and efficiency of the image generation process.
Notably, the study highlights that the improvement in model performance is not merely a result of increased model capacity but rather reflects the importance of respecting latent topology in generative modeling. Subsequent scaling to the DiT-XL architecture also yielded promising results, achieving an FID of 3.62 within 80 epochs, suggesting RJF’s method is scalable and efficient.
The findings underscore a new paradigm in generative modeling, moving beyond traditional width amplification approaches, which often fail to address the underlying geometric constraints inherent in representation learning. The authors pointed out limitations in the projection radius during inference, hinting at future research avenues that may optimize this aspect and explore broader implications for manifold alignment across diverse latent spaces.
This research not only provides a significant leap in the efficacy of image generation techniques but also sets a foundation for future innovations in the field of artificial intelligence. By addressing fundamental geometric issues, the study paves the way for more accurate and efficient generative models, potentially transforming applications in various domains, including art, design, and data augmentation.
👉 More information
🗞 Learning on the Manifold: Unlocking Standard Diffusion Transformers with Representation Encoders
🧠 ArXiv: https://arxiv.org/abs/2602.10099
 Mistral AI Invests €1.2B in Swedish Data Center to Boost European AI Infrastructure
Mistral AI Invests €1.2B in Swedish Data Center to Boost European AI Infrastructure AI Sector Plummets 12.1%, Losing $2.8B as TAO and NEAR Hit Record Lows
AI Sector Plummets 12.1%, Losing $2.8B as TAO and NEAR Hit Record Lows Nvidia’s Rubin Chip Revolutionizes AI Inference, Ensuring Dominance Amidst Competition
Nvidia’s Rubin Chip Revolutionizes AI Inference, Ensuring Dominance Amidst Competition Google’s AI Tools Block Disney Character Prompts Amid Copyright Concerns
Google’s AI Tools Block Disney Character Prompts Amid Copyright Concerns