Major generative artificial intelligence models recently underwent a nationwide mock exam in South Korea, revealing significant disparities in performance across various subjects. The exam, administered by Jongno Academy, evaluated the models on the Korean, math, and English sections, with results released on March 31. The scores indicated that while some models displayed proficiency suitable for admission to top universities, others fell well below average.
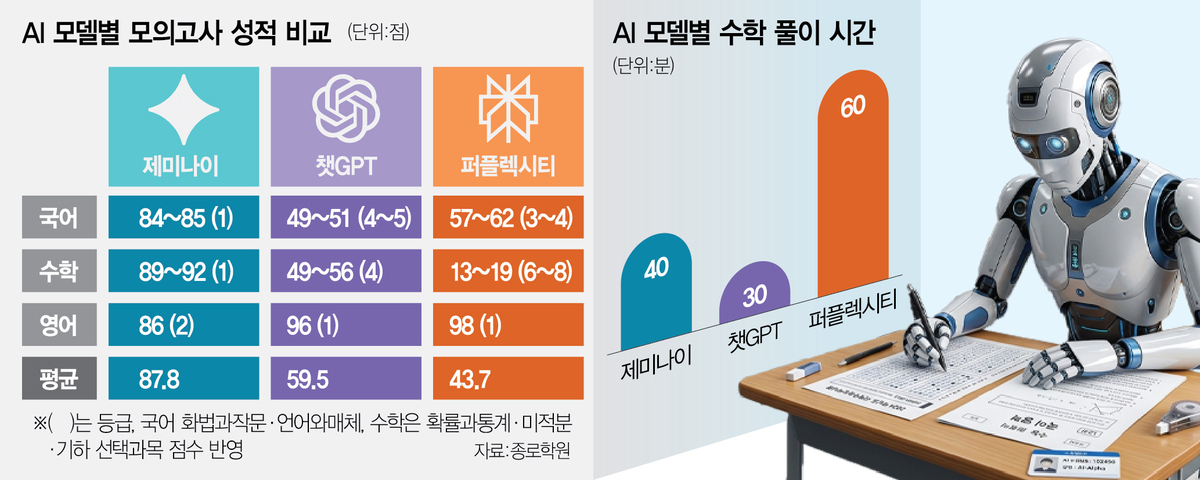
The standout performer was Google’s Gemini, which achieved an average score of 87.8. In contrast, OpenAI’s ChatGPT scored 59.5, and Perplexity lagged further behind with an average score of 43.7. When translated into grade levels, Gemini reached Grade 1 in both Korean and math and Grade 2 in English, meeting the criteria for applying to prestigious institutions referred to as “SKY” universities, which include Seoul National University, Yonsei University, and Korea University.
ChatGPT, on the other hand, was classified broadly at Grade 4, while Perplexity dropped to Grades 6 through 8 in math, illustrating a stark performance gap among the models. The tests used paid subscription versions of each AI model, with a noticeable time difference in how long they took to complete the subjects. Gemini required approximately 40 minutes for the math section, ChatGPT took about 30 minutes, and Perplexity needed roughly one hour.
The math portion showcased the most pronounced discrepancies. Perplexity scored a mere 19 in probability and statistics, 13 in calculus, and 13 in geometry. In stark contrast, Gemini achieved scores of 92, 91, and 89 in the same areas, highlighting its superior performance. ChatGPT’s scores hovered in the 40-to-50-point range across elective subjects, reinforcing the notion of a technological divide among these models. Jongno Academy noted that the differences were particularly evident in questions requiring more complex conditions or step-by-step solution processes.
The scores in Korean also varied significantly, reflecting differences in reading comprehension skills. Gemini maintained Grade 1 levels with scores of 84 in speech and composition and 85 in language and media, while the other models struggled to achieve scores between 40 and 60. All three models saw decreased accuracy on non-literary questions in the reading and literature sections, which demanded the ability to synthesize multiple pieces of information.
Some models even made errors on straightforward questions, particularly those with a high overall correct-answer rate. One notable example involved a question requiring test-takers to identify issues based on conversational context related to smart farm data. Despite its simplicity, some models failed to integrate the relevant information correctly. Lim Sung-ho, CEO of Jongno Academy, remarked, “The fact that AI answered this wrong despite it being an ordinary question at the middle school third-year level shows that AI still lacks the ability to organically connect presented information.”
In English, where the language barrier is less pronounced, all three models exhibited stable performance. Perplexity scored highest at 98, followed by ChatGPT at 96 and Gemini at 86. However, they collectively struggled with questions requiring advanced logical reasoning, such as those involving inference and indirect writing tasks.
Experts emphasize that while AI can learn from vast datasets, effective analysis and judgment still depend on foundational human knowledge and literacy. Park Nam-gi, professor emeritus at Gwangju National University of Education, stated, “Even if AI learns from vast amounts of data, precise analysis and judgment ultimately require a foundation of human basic knowledge and literacy. Just as one cannot ask the right questions without foundational knowledge, cultivating basic concepts and critical thinking through foundational learning remains the most important task in education.”
As generative AI continues to develop, these findings underline the necessity for ongoing improvements in contextual understanding and problem-solving capabilities. The gap in performance among leading models raises questions about their applicability in educational settings and their potential roles in supporting learning outcomes.
See also Artlist Integrates Google’s Lyria 3 Pro, Enables 3-Minute AI Track Generation
Artlist Integrates Google’s Lyria 3 Pro, Enables 3-Minute AI Track Generation AI Adoption Surges in Higher Education as 84.82 Sentiment Index Signals Transformative Change
AI Adoption Surges in Higher Education as 84.82 Sentiment Index Signals Transformative Change Google Launches Veo 3.1 Lite for Developers, Enhancing Cost-Effective AI Video Access
Google Launches Veo 3.1 Lite for Developers, Enhancing Cost-Effective AI Video Access Nvidia Stock Hits Critical Neckline as AI Memory Sell-Off Leads to 9% Decline
Nvidia Stock Hits Critical Neckline as AI Memory Sell-Off Leads to 9% Decline AI Adoption in Higher Education Surges: 84% Positive Sentiment, Major Partnerships Formed
AI Adoption in Higher Education Surges: 84% Positive Sentiment, Major Partnerships Formed