A significant update to llama.cpp, a popular library for running large language models (LLMs), was merged on April 18, introducing a feature called speculative checkpointing. This enhancement reduces video RAM (VRAM) usage by up to 40% and increases token throughput by as much as 20%, making it easier for users to run high-parameter models on consumer hardware.
Georgi Gerganov, the original author of llama.cpp, led this architectural change, which he describes as one of the most important performance updates in recent years. The update addresses a critical bottleneck faced by users employing large models locally: the need to synchronize and back up the entire Key-Value cache during inference, particularly when rollbacks are necessary during speculative decoding. This synchronization can lead to increased memory overhead, especially on hardware with limited memory bandwidth, such as Apple M-series chips and consumer NVIDIA RTX GPUs.
The traditional approach to managing memory during these operations posed significant challenges, often leading to memory exhaustion when attempting to process extended context windows. Speculative checkpointing mitigates this issue by maintaining a lightweight snapshot of changes instead of flushing the entire cache, which results in substantial efficiency gains. Benchmarks from the merge discussion highlight the practical benefits, noting up to a 40% reduction in VRAM usage during batched operations and a 15% to 20% improvement in tokens-per-second throughput on bandwidth-constrained consumer hardware. For users handling 70 billion-parameter models with extensive context, these improvements can mean the difference between a successful inference and failure.
The timing of this update coincides with the growing popularity of speculative decoding, a technique accelerated by research from DeepMind. Until now, the integration of this technique within llama.cpp was hamstrung by its memory consumption, which limited throughput on typical consumer systems. The introduction of speculative checkpointing changes the calculus, making the technique feasible for local inference setups, which often operate under tighter resource constraints.
The implications of this development extend beyond individual users experimenting with open-source models. Companies focused on edge computing and privacy-conscious enterprises that rely on local inference have long faced challenges regarding the economics and hardware demands of running large models on-premises. The reduction in VRAM requirements for high-context inference makes local deployment more attractive, potentially shifting some workloads away from cloud-based APIs.
Following the merge, downstream projects such as Ollama, LM Studio, and GPT4All have quickly begun tracking integration from the latest master branch. This rapid uptake indicates that the practical benefits of the update will likely spread through the local AI ecosystem within days, rather than weeks.
The recent merge comes after a thorough period of community review and benchmarking, suggesting that the implementation is stable. However, real-world performance across the diverse hardware configurations used by the llama.cpp user base will take time to fully evaluate. Stress tests involving long context windows and specific quantization formats may reveal unexpected issues, which are expected to emerge over the coming weeks as adoption widens.
Beyond the immediate technical improvements, this update underscores a broader trend that has characterized llama.cpp since the introduction of GGML quantization: incremental, community-driven enhancements that build on existing capabilities. While server-grade inference remains quicker in absolute terms, the gap between local capabilities and those that necessitate cloud resources is steadily narrowing. The introduction of speculative checkpointing marks a significant stride towards making local inference more viable, and its ripple effects throughout the open-source ecosystem warrant close observation in the months ahead.
Also read: AI’s Hidden Bottleneck Is Not Silicon. It Is Copper. • Nvidia Walks Away From Gamers, And The Numbers Tell The Story • The AI experience is splitting in two and the gap is growing faster than most people realize.
See also Uber Eats Revamps Recommendation Model, Reduces Data Lag to Seconds with Generative AI
Uber Eats Revamps Recommendation Model, Reduces Data Lag to Seconds with Generative AI 15 Powerful AI Tools for Everyday Tasks: Explore Top Platforms and Features
15 Powerful AI Tools for Everyday Tasks: Explore Top Platforms and Features Korean ETRI Unveils AI Technologies for Media Transformation at NAB 2026
Korean ETRI Unveils AI Technologies for Media Transformation at NAB 2026 SEO Remains Essential as Experts Misinterpret Generative Engine Optimization Strategies
SEO Remains Essential as Experts Misinterpret Generative Engine Optimization Strategies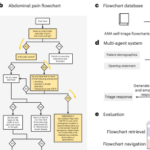 Multi-Agent Framework Integrates Large Language Models with Medical Flowcharts for Self-Triage
Multi-Agent Framework Integrates Large Language Models with Medical Flowcharts for Self-Triage