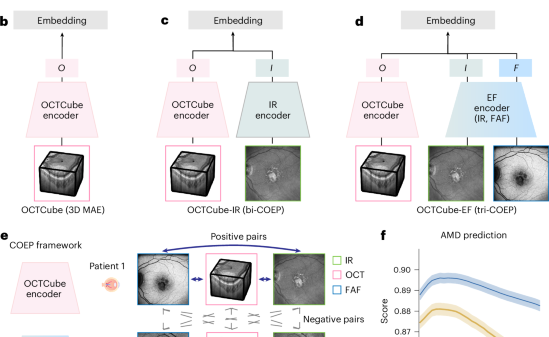
Graphics processing units (GPUs) have emerged as the primary upgrade for companies enhancing their AI systems, particularly in the inferencing stage, where trained models produce outputs from new data. However, semiconductor firm AMD warns that solely depending on GPUs can hinder performance and escalate costs.
In a recent interview with Newsbytes.PH, AMD’s Asia Pacific general manager, Alexey Navolokin, emphasized the growing need for effective coordination among CPUs, GPUs, memory, and networking as AI workloads expand and agentic AI systems shift towards real-world applications.
“Today’s large models operate across clusters of GPUs that must work in parallel and exchange data constantly,” Navolokin explained. He noted that overall performance hinges not only on GPU speed but also on the efficiency with which data is transferred and computation is coordinated across the entire system architecture.
Navolokin pointed out a prevalent misconception that GPUs serve as the singular powerhouse for AI inferencing. He highlighted that modern AI models typically exceed the capacity of a single device, necessitating substantial support from host CPUs to facilitate data movement, synchronization, and latency-sensitive tasks. “A fast CPU keeps the GPU fully utilized, reduces overhead in the inference pipeline, and cuts end-to-end latency,” he stated, adding that even minor reductions in CPU delays can significantly enhance application responsiveness.
Tokenization, the process of converting inputs into numerical units, is heavily reliant on the interaction between CPU and GPU. “Inference runs token by token, and tasks such as tokenization, batching, and synchronization sit directly on the critical path,” Navolokin said. “Delays on the host CPU can slow the entire response.”
Beyond performance, Navolokin argued that optimizing CPU-GPU balance can lead to lower infrastructure costs by increasing GPU utilization and decreasing hardware requirements. “Higher efficiency enables teams to meet demand with fewer CPU cores or GPU instances,” he noted.
He cited a case study involving South Korean IT firm Kakao Enterprise, which reportedly reduced its total cost of ownership by 50% and its server count by 60%, while improving AI and cloud performance by 30% after deploying AMD’s EPYC processors.
The fifth-generation EPYC processors, according to Navolokin, can deliver comparable integer performance to earlier systems while using up to 86% fewer racks, effectively lowering both power consumption and software licensing requirements. He added that the demand for CPUs is exacerbated by the rise of agentic AI systems, designed to plan, reason, and act autonomously.
“These systems generate significantly more CPU-side work than traditional inference,” Navolokin explained. “Tasks such as retrieval, prompt preparation, multi-model routing, and synchronization are CPU-driven.” In these scenarios, the CPU functions as a control node across distributed resources that span data centers, cloud platforms, and edge systems.
AMD is focusing its EPYC processors as host CPUs for these demanding workloads. The latest EPYC 9005 Series boasts up to 192 cores, expanded AVX-512 execution, DDR5-6400 memory support, and PCIe Gen 5 I/O—features designed to support large-scale inferencing and GPU-accelerated systems. Navolokin mentioned that this latest generation shows a 37% improvement in instructions per cycle for machine learning and high-performance computing workloads compared to previous EPYC processors.
He also referenced Malaysian reinsurance firm Labuan Re, which anticipates reducing its insurance assessment turnaround time from weeks to less than a day after migrating to an EPYC-powered AI platform.
As AI deployments extend beyond centralized data centers, Navolokin urged organizations to rethink their infrastructure design. “The priority should not be the performance of a single compute resource, but the ability to deploy AI consistently across heterogeneous environments,” he advised. He underscored the importance of open platforms and distributed compute strategies, noting that real-time inference often runs more efficiently on edge devices or AI PCs closer to data sources.
“Success in inferencing is no longer defined solely by raw compute power,” Navolokin concluded. “It depends on latency, efficiency, and the ability to operate across data center, cloud, and edge environments.”
See also AI Transforms Missile Guidance: Neural Networks Enhance Target Engagement and Adaptivity
AI Transforms Missile Guidance: Neural Networks Enhance Target Engagement and Adaptivity NASA Integrates AI in Artemis and VIPER Missions to Enhance Lunar Exploration and Data Processing
NASA Integrates AI in Artemis and VIPER Missions to Enhance Lunar Exploration and Data Processing AMD and Google Partner with Samsung for U.S. 2nm AI Chip Production in Texas
AMD and Google Partner with Samsung for U.S. 2nm AI Chip Production in Texas Study Reveals AI in Healthcare Reflects Human Biases, Challenging Accountability Norms
Study Reveals AI in Healthcare Reflects Human Biases, Challenging Accountability Norms SMCI Scales Rack Capacity to 6,000 Monthly Amid Rising AI Demand
SMCI Scales Rack Capacity to 6,000 Monthly Amid Rising AI Demand